

Measurement of Transgene Copy Number in Plants Using Droplet Digital PCR
应用微滴数字PCR技术测定植物中的转基因拷贝数
发布: 2021年07月05日第11卷第13期 DOI: 10.21769/BioProtoc.4075 浏览次数: 5892
评审: Charukesi RajuluTom Lawrenson
参见作者原研究论文
The authors used this protocol in:

Dec 2020









Abstract
Transgenic plants are produced both to investigate gene function and to confer desirable traits into crops. Transgene copy number is known to influence expression levels, and consequently, phenotypes. Similarly, knowledge of transgene zygosity is desirable for making quantitative assessments of phenotype and tracking the inheritance of transgenes in progeny generations. Since the first transgenic plants were produced, several methods for determining copy number have been applied, including Southern blotting, quantitative real-time PCR, and more recently, sequencing methods; however, each method has specific disadvantages, compromising throughput, accuracy, or expense. Digital PCR (dPCR) divides reactions into partitions, converting the exponential, analogue nature of PCR into a linear, digital signal that allows the frequency of occurrence of specific sequences to be accurately estimated. Confidence increases with the number of partitions; therefore, the availability of emulsion technologies that enable reactions to be divided into tens of thousands of nanodroplets allows accurate determination of copy number in what has become known as digital droplet PCR (ddPCR). ddPCR offers similar benefits of low costs and scalability as other PCR techniques but with superior accuracy and reliability.
Graphic abstract:
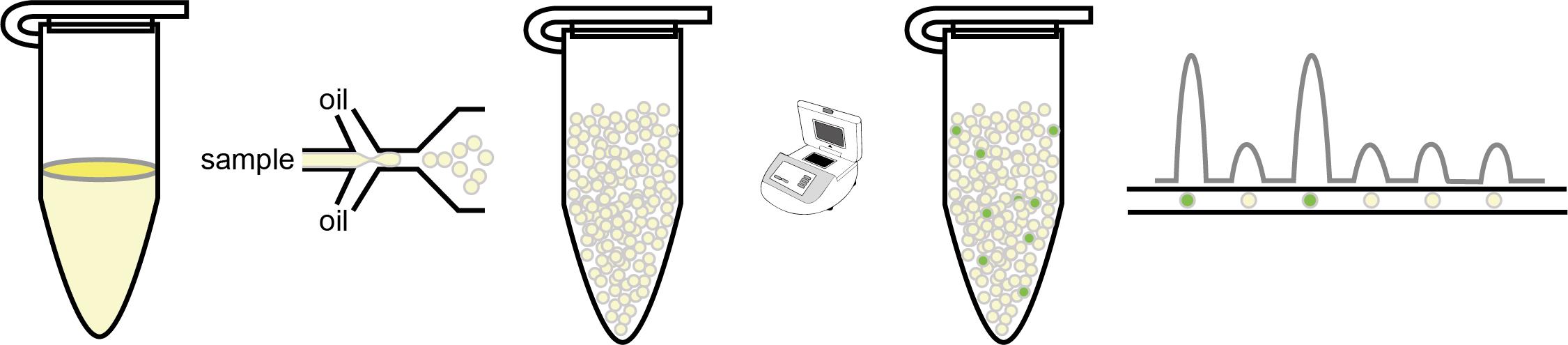
Digital PCR (dPCR) divides reactions into partitions, converting the exponential, analogue nature of PCR into a linear, digital signal that allows the frequency of transgene copy number to be accurately assessed.
Background
Plant transformation is used as a research tool to investigate gene function as well as for the production of genetically engineered crops. Several methods are used to deliver DNA into plant cells, including direct delivery into isolated protoplasts, biolistic delivery using high-density microparticles, Agrobacterium tumefaciens-mediated delivery, and most recently, nanoparticles (Altpeter et al., 2016; Wang et al., 2019). DNA delivery techniques can be optimized to obtain a higher frequency of transgenic lines with single or low-copy insertions; however, the exact number of transgenes transferred to the plant genome cannot be controlled or limited, and transgenic lines must be individually assessed to determine transgene copy number (Sivamani et al., 2015). Since expression levels, and consequently phenotypes, have long been acknowledged to be influenced by copy number, accurate determination is essential (Hobbs et al., 1993). Copy number determination can also be used to track inheritance and zygosity. Most methods of plant transformation deliver transgenes to somatic cells from which transgenic plants (referred to as T0) are regenerated, each with one more hemizygous transgenic locus. In progeny resulting from self-fertilization, transgenic loci usually follow classical Mendelian inheritance; although, non-Mendelian segregation has also been reported (Ahuja and Fladung, 2014). Accurate determination of copy number can be used to track transgenes through progeny generations, being particularly useful in lines with multiple transgene copies and in obligate outcrossing species.
In the decades since plant transformation became routine, a number of different technologies have been used to determine copy number. Initially, copy number was determined by Southern hybridization analysis (Southern, 1975). In this technique, genomic DNA is digested with a restriction endonuclease, separated by electrophoresis, and following transfer to a membrane, fragments containing the transgene are detected using a labeled DNA probe. As well as being laborious, it can be challenging to detect transgenes inserted close together (in tandem repeats), which are likely to be on the same fragment. Further, unless there is sufficient heterozygosity so that homologous chromosomes have different fragmentation patterns after restriction digestion, detection of zygosity is reliant on differences in band intensity, which is considered unreliable (Cantsilieris et al., 2013).
In the first decades of the twenty-first century, quantitative real-time PCR (qPCR) became the method of choice for estimating plant transgene copy number (Bubner and Baldwin, 2004; Li et al., 2004; Weng et al., 2004; Yang et al., 2005a and 2005b; Yi and Hong, 2019). The concentration of the transgene in each sample is compared with either a standard curve or a validated reference gene (an endogenous gene of known copy number) (Pfaffl, 2001). However, since each cycle of PCR is a doubling reaction, the two-fold increase required to differentiate one copy from two copies, or a hemizygote from a homozygote, is at the detection limit. Even with optimization, it can be challenging to achieve the levels of accuracy required to distinguish single copy and two-copy lines (Cantsilieris et al., 2013; Mieog et al., 2013).
Next-generation sequencing (NGS) technologies have reduced the cost of sequencing; however, even low-pass shallow sequencing, sometimes called ‘skim-sequencing,’ is expensive for large plant genomes – prohibitively so for routine copy number detection (Golicz et al., 2015; Kim et al., 2016). Targeted-capture sequencing, in which regions of the genome containing sequences of interest are isolated, has allowed the generation of accurate copy number data together with information on the sequence identity of insertion sites at reduced costs (Guttikonda et al., 2016). Initially, short-read next-generation sequencing technologies were applied (Polkoa et al., 2012; Lepage et al., 2013; Guo et al., 2016), but more recently, long-read nanopore-based sequencing platforms have also been utilized (Li et al., 2019; Boutigny et al., 2020). However, compared with PCR-based methods, even capture sequencing techniques have higher costs and require more time for sample preparation and data analysis.
Digital PCR (dPCR) converts the exponential, analogue nature of PCR into a linear, digital signal allowing accurate estimations of the frequency of occurrence of specific sequences (Vogelstein and Kinzler, 1999). To do this, each sample is divided into a large number of partitions, and PCR reactions are carried out on each partition individually. This was initially difficult and laborious as reactions needed to be divided across multiple compartments (tubes), but the development of emulsion technologies enabled the reaction to be compartmentalized in nanodroplets within a single tube (Diehl et al., 2006). In common with qPCR protocols, fluorescence is incorporated into the target amplicon; however, instead of monitoring fluorescence intensity at a specific cycle during the exponential phase of the reaction, the presence or absence of fluorescence (and therefore the target) at the reaction endpoint is determined for each partition. The copy number of the target gene is calculated by determining the fraction of partitions in which the target gene was amplified relative to a reference gene of known copy number. As each partition is scored for the presence of fluorescence, dPCR achieves precise quantitation of the transgene copy number. Confidence is improved by increasing population size (counting more partitions), resulting in the accuracy of copy number estimation by dPCR being reported as superior to qPCR and comparative with sequencing techniques (Abyzov et al., 2012). In recent years, a number of commercial platforms that divide reactions into tens of thousands of compartments using emulsion technology (digital droplet PCR; ddPCR) or microfluidics chips have been successfully applied for the accurate determination of transgene copy number in different plant species (Glowacka et al., 2016; Collier et al., 2017; Giraldo et al., 2019; Cai et al., 2020). Below, we describe a ddPCR protocol used to determine the transgene copy number in Arabidopsis plants (Cai et al., 2020).
Materials and Reagents
ddPCR set-up and droplet generation
PCR Plate Heat Seal, foil, pierceable (Bio-Rad, catalog number: 1814040)
DG8TM Cartridge for QX200TM/QX100TM Droplet Generator (Bio-Rad, catalog number: 1864008)
Droplet Generator DG8TM Gasket (Bio-Rad, catalog number: 1863009)
ddPCR Plates, 96-Well, Semi-Skirted (Bio-Rad, catalog number: 12001925)
QubitTM dsDNA HS Assay kit (ThermoFisher Scientific, catalog number: Q32851)
Restriction endonuclease with a recognition site within the transgene but not between the primer sites (see procedure for details) and compatible digestion buffer
QX200TM ddPCR TM EvaGreen Supermix (Bio-Rad, catalog number: 1864033)
QX200 Droplet Generation Oil for EvaGreen® (Bio-Rad, catalog number: 1864005)
Equipment
ddPCR set-up and droplet generation
QubitTM 4 fluorometer (ThermoFisher Scientific, catalog number: Q33238)
QX200TM droplet generator (Bio-Rad, catalog number: 1864002)
Thermal cycler (e.g., Bio-Rad C1000 Touch thermal cycler, catalog number: 1851148)
Multichannel pipettes (10-100 µl)
Heat sealer (e.g., Eppendorf S100, catalog number: 5391000036)
DG8 cartridge holder (Bio-Rad, catalog number: 1863051)
QX200 droplet reader (Bio-Rad, catalog number: 1864003)
Droplet reader plate holder (Bio-rad, catalog number: 12006834)
Software
Primer design software, e.g., Primer 3 (https://primer3.ut.ee/)
Sequence analysis software, e.g., Benchling (https://benchling.com)
QuantaSoft software (Bio-Rad, catalog number: 1863007)
Software capable of reading comma-separated values (.csv) files (e.g., Microsoft Excel)
Droplet DigitalTM PCR Applications Guide
http://www.bio-rad.com/webroot/web/pdf/lsr/literature/Bulletin_6407.pdf
Procedure
文章信息
版权信息
© 2021 The Authors; exclusive licensee Bio-protocol LLC.
如何引用
Cai, Y., Dudley, Q. M. and Patron, N. J. (2021). Measurement of Transgene Copy Number in Plants Using Droplet Digital PCR. Bio-protocol 11(13): e4075. DOI: 10.21769/BioProtoc.4075.
分类
分子生物学 > DNA > PCR
植物科学 > 植物分子生物学 > DNA
您对这篇实验方法有问题吗?
在此处发布您的问题,我们将邀请本文作者来回答。同时,我们会将您的问题发布到Bio-protocol Exchange,以便寻求社区成员的帮助。