

EmPC-seq: Accurate RNA-sequencing and Bioinformatics Platform to Map RNA Polymerases and Remove Background Error
EmPC-seq: 使用精确的RNA测序和生物信息学平台绘制RNA聚合酶并消除背景错误
(*contributed equally to this work) 发布: 2021年02月20日第11卷第4期 DOI: 10.21769/BioProtoc.3921 浏览次数: 6295
评审: Emilia KrypotouMostafa RahnamaPrashanth N Suravajhala
参见作者原研究论文
The authors used this protocol in:

Jun 2020
Advertisement










Abstract
Transcription errors can substantially affect metabolic processes in organisms by altering the epigenome and causing misincorporations in mRNA, which is translated into aberrant mutant proteins. Moreover, within eukaryotic genomes there are specific Transcription Error-Enriched genomic Loci (TEELs) which are transcribed by RNA polymerases with significantly higher error rates and hypothesized to have implications in cancer, aging, and diseases such as Down syndrome and Alzheimer’s. Therefore, research into transcription errors is of growing importance within the field of genetics. Nevertheless, methodological barriers limit the progress in accurately identifying transcription errors. Pro-Seq and NET-Seq can purify nascent RNA and map RNA polymerases along the genome but cannot be used to identify transcriptional mutations. Here we present background Error Model-coupled Precision nuclear run-on Circular-sequencing (EmPC-seq), a method combining a nuclear run-on assay and circular sequencing with a background error model to precisely detect nascent transcription errors and effectively discern TEELs within the genome.
Keywords: Transcriptional mutagenesis (转录诱变)Background
Transcriptional errors due to ribonucleotide misincorporation are ubiquitous to all living organisms (Carey, 2015). Given that each messenger RNA (mRNA) can be translated 2-4 thousand times (Schwanhausser et al., 2011) and many special RNAs are expressed only once per cell at a given time (Islam et al., 2011; Pelechano et al., 2010), even a single transcription error at a critical residue can make large differences in a specific protein’s expression. In addition, transcriptional errors can accelerate protein aggregation leading to age-related diseases in humans (van Leeuwen et al., 1998). While transcription errors are conventionally held to have a random distribution across the genome, there is evidence indicating that transcription errors could be enriched at certain structural motifs and specific genomic regions (Imashimizu et al., 2013; van Leeuwen et al., 1998). These Transcription Error-Enriched genomic Loci (TEELs) have notable biological significance in various diseases such as Down syndrome and Alzheimer’s and are gaining attention in genetics research (Burns et al., 2010; Saxowsky et al., 2008). Unfortunately, there are major challenges that must be circumvented for the study of transcriptional error due to RNA polymerase unconfounded by RNA-editing processes such as those from post-transcriptional modifications. This requires purification of nascent RNA coupled with a highly accurate RNA sequencing method that can identify TEELs and elucidate transcriptional regulation and dysregulation contributing to transcriptional errors with implications to diseases.
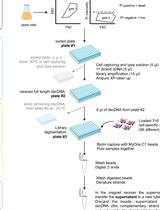
There are several complications which impede the accurate detection of de novo transcription errors. The first challenge is eliminating the noise from post-transcriptional modifications, which requires the purification of nascent RNA freshly made by RNA polymerases. Hence, current RNA sequencing (RNA-seq) studies on transcriptional errors often overlook this requirement and therefore overestimate transcription error rates. The second challenge is rectifying the systematic noise from Next Generation Sequencing (NGS). NGS on average misreads approximately one base in every 1,000 (Minoche et al., 2011), and this is further compounded by the fact that reverse transcriptase (required for generating cDNA for NGS) misincorporates one base in every 10,000 (Ji and Loeb, 1992). The third challenge is computationally discerning TEELs from background noise. Even with accurate sequencing data, it is still difficult to computationally identify TEELs amongst background errors which are stochastically introduced by RNA polymerases (de Mercoyrol et al., 1992). Here, we present our background Error Model-coupled Precision nuclear run-on Circular-sequencing (EmPC-seq) method (Figure 1) to overcome these three main challenges. EmPC-seq consists of three core components: (1) a nuclear run-on assay to capture nascent RNA before post-transcriptional modifications (Mahat et al., 2016), (2) a circular-resequencing step that generates cDNA via rolling-cycle reverse transcription of circularized nascent RNA molecules (Acevedo and Andino, 2014) to improve sequencing accuracy by generating tandem cDNA repeats of the same circularized RNA molecule by rolling circle amplification so that the RNA molecule can be sequenced multiple times. (3) We also developed a background error model algorithmic analysis to remove stochastic background noise by simulating de novo sequencing data and subsequent error to serve as a control group carrying background alterations from sequencing noise, non-uniform sequencing depth, and alignment artifacts (Cheung et al., 2020). EmPC-seq aims to detect nascent transcriptional errors and elucidate their origins that may have implications to diseases.

Figure 1. Schematic of EmPC-seq. Real transcription errors are represented using orange dots. Dots in other colors represent systematic noise, including enzymatic errors and sequencing errors. (Step 1) Yeast cell is permeabilized. (Step 2) In vivo transcription is halted by adding all 4 kinds of biotinylated NTPs during the Nuclear Run-on assay. (Step 3) Yeast total RNA is extracted and purified via ethanol precipitation. (Step 4) RNA is fragmented with base hydrolysis into short (60-100nt) RNAs. (Step 5) Biotin-labeled nascent RNA is enriched through Streptavidin bead purification. (Step 6) Re-purified nascent RNAs are circularized by RNA ligase and processed into tandem copy cDNAs through rolling circle reverse transcription. (Step 7) Library DNA is prepared with a kit and then submitted for Next Generation Sequencing. (Step 8) Transcription errors are accurately detected by combining consensus sequence results with our background error model. This schematic is adapted from Cheung et al. (2020).
Materials and Reagents
1.5 ml tubes
Pipette tips
Cuvettes
0.22 μm filter
W303 yeast cells (GenBank Number: JRIU00000000)
1 M Dithiothreitol (DTT, ThermoFisher, catalog number: P2325 )
Diethyl pyrocarbonate (Sigma, catalog number: 40718 )
UltraPureTM DNase/RNase-Free Distilled Water (ThermoFisher, catalog number: 10977015 )
Yeast Extract (Sigma, catalog number: Y1625 )
Peptone (Sigma, catalog number: P0556 )
D-(+)-Glucose (Sigma, catalog number: G8270 )
Adenine (Sigma, catalog number: A8626 )
N-Lauroylsarcosine sodium salt, Sarkosyl (Sigma, catalog number: L9150 )
Trizma® hydrochloride (Sigma, catalog number: T5941 )
Potassium chloride (Sigma, catalog number: P9333 )
Magnesium chloride (Sigma, catalog number: M8266 )
Biotinylated Nucleotides (Jena Bioscience, catalog number: NU series )
RNase Inhibitor, Murine (NEB, catalog number: M0314L )
Diethyl pyrocarbonate, DEPC (Sigma, catalog number: 40718 )
Liquified Phenol (Sigma, catalog number: P9346 )
Sodium acetate (Sigma, catalog number: S2889 )
Ethylenediaminetetraacetic acid, EDTA (Sigma, catalog number: EDS )
Sodium dodecyl sulfate (Sigma, catalog number: L3771 )
Chloroform (Sigma, catalog number: C2432 )
GlycoBlueTM Coprecipitant (ThermoFisher, catalog number: AM9515 )
Ethyl alcohol, Pure (Sigma, catalog number: E7023 )
Sodium hydroxide (Sigma, catalog number: S8045 )
TritonTM X-100 (Sigma, catalog number: X100 )
Monarch® RNA Cleanup Kit (NEB, catalog number: T2030L )
DynabeadsTM M-280 Streptavidin (ThermoFisher, catalog number: 60210 )
Sodium chloride (Sigma, catalog number: S7653 )
TRIzolTM Reagent (ThermoFisher, catalog number: 15596018 )
AmbionTM T4 RNA Ligase (ThermoFisher, catalog number: AM2141 )
T4 Polynucleotide Kinase (NEB, catalog number: M0201S )
Polyethylene glycol 8000 (Sigma, catalog number: 1546605 )
Adenosine 5'-Triphosphate, ATP (NEB, catalog number: P0756S )
dNTP Mix (ThermoFisher, catalog number: 18427088 )
Random Hexamer Primer (ThermoFisher, catalog number: SO142 )
SuperScriptTM III First-Strand Synthesis System (ThermoFisher, catalog number: 18080051 )
NEBNext® UltraTM II Directional RNA Second Strand Synthesis Module (NEB, catalog number: E7550L )
MinElute PCR Purification Kit Print (QIAGEN, catalog number: 28004 )
NEBNext® UltraTM II DNA Library Prep Kit for Illumina® (NEB, catalog number: E7645L )
QubitTM dsDNA HS Assay Kit (ThermoFisher, catalog number: Q32851 )
YEPD medium (see Recipes)
2.5× Transcription buffer (see Recipes)
AES Buffer (see Recipes)
Beads washing buffer (see Recipes)
Binding washing buffer (see Recipes)
Low Salt washing buffer (see Recipes)
High Salt washing buffer (see Recipes)
DEPC-H2O (see Recipes)
1 M sodium acetate solution (see Recipes)
Equipment
Eppendorf® Research® Plus Pipettes (Eppendorf, catalog number: EP series )
MaxQTM 6000 Incubated/Refrigerated Stackable Shakers (ThermoFisher, catalog number: SHKE6000 )
Eppendorf BioPhotometer® (Eppendorf, model: D30 )
Megafuge® (Heraeus, model: 1.0R )
5 Liter General Purpose Water Bath (PolyScience, catalog Number: WBE05A11B )
NEBNext® Magnetic Separation Rack (NEB, catalog number: S1515S )
Roto-Shake Genie® (Zymo Research, catalog number: S5008 )
ProFlex PCR System (ThermoFisher, catalog number: 4484075 )
5200 Fragment Analyzer System (Agilent, catalog number: M5310AA )
Software
ProSize (Agilent, https://explore.agilent.com/Software-Download-Fragment-Analyzer-Prosize)
Python (version 2.7.12, https://www.python.org/)
Cython (version 0.23.4, https://cython.org/)
NumPy (version 1.11.0, https://numpy.org/)
SciPy (version 0.17.0, https://www.scipy.org/)
Burrows-Wheeler Aligner (version 0.7.17-r1188, http://bio-bwa.sourceforge.net/)
samtools (version 1.9, http://www.htslib.org/)
pysam (version 0.15.0, https://pysam.readthedocs.io/en/latest/installation.html)
matplotlib (version 2.2.2, https://matplotlib.org/)
Procedure
文章信息
版权信息
© 2021 The Authors; exclusive licensee Bio-protocol LLC.
如何引用
Wang, Y., Chong, T. H., Unarta, I. C., Xu, X., Suarez, G. D., Wang, J., Lis, J. T., Huang, X. and Cheung, P. (2021). EmPC-seq: Accurate RNA-sequencing and Bioinformatics Platform to Map RNA Polymerases and Remove Background Error. Bio-protocol 11(4): e3921. DOI: 10.21769/BioProtoc.3921.
分类
系统生物学 > 转录组学 > RNA测序
分子生物学 > RNA > 转录
您对这篇实验方法有问题吗?
在此处发布您的问题,我们将邀请本文作者来回答。同时,我们会将您的问题发布到Bio-protocol Exchange,以便寻求社区成员的帮助。