- Protocols

- Articles and Issues
- For Authors
- About
- Become a Reviewer

Dissociating Behavior and Spatial Working Memory Demands Using an H Maze
Published: Vol 11, Iss 5, Mar 5, 2021 DOI: 10.21769/BioProtoc.3947 Views: 4144
Reviewed by: Soyun KimMohammed Mostafizur RahmanArnau Busquets-Garcia
Original research article
The authors used this protocol in:

May 2020

Protocol Collections
Comprehensive collections of detailed, peer-reviewed protocols focusing on specific topics







Abstract
The development of mazes for animal experiments has allowed for the investigation of cognitive maps and place cells, spatial working memory, naturalistic navigation, perseverance, exploration, and choice and motivated behavior. However, many mazes, such as the T maze, currently developed to test learning and memory, do not distinguish temporally and spatially between the encoding and recall periods, which makes it difficult to study these stages separately when analyzing animal behavior and electrophysiology. Other mazes, such as the radial maze, rely on single visits to portions of the maze, making maze coverage sparse for place cell and electrophysiology experiments. In this protocol, we present instructions for building and training an animal on a spatial appetitive choice task on a low-cost double-sided T (or H) maze. This maze has several advantages over the traditional T maze and radial mazes. This maze is unique in that it temporally and directionally dissociates the memory encoding and retrieval periods, while requiring the same behaviors of the animal during both periods. This design allows for independent investigation of brain mechanisms, such as cross-region theta coordination, during memory encoding and retrieval, while at least partially dissociating these stages from behavior. This maze has been previously used in our laboratory to investigate cell firing, single-region local field potential (LFP) patterns, and cross region LFP coherence in the hippocampus, lateral septum, prefrontal cortex, and ventral tegmental area, as well as to investigate the effects of hippocampal theta perturbations on task performance.
Keywords: Spatial navigationBackground
Mazes have been used in psychology, animal behavior, and neuroscience experiments for well over a century (Dudchenko, 2004; Fortin, 2008). In controlled laboratory settings, mazes have allowed for the investigation of cognitive maps and place cells, spatial working memory, naturalistic navigation, perseverance, exploration, and choice and motivated behavior (Tolman et al., 1946 and 1948; Roberts et al., 1962; Lash, 1964; Kimble and Kimble, 1965; O'Keefe and Nadel, 1978; Brito and Thomas, 1981; Wiener et al., 1989; Redish and Touretzky, 1998; Hollup et al., 2001; Huxter et al., 2001; Deacon and Rawlins, 2006; Ainge et al., 2007; Gupta et al., 2012; Tanila et al., 2018).
After early maze experiments established that animals have a proclivity to spontaneously alternate between two spatial choices (Carr, 1917), Tolman became one of the first researchers to use a T-maze to formally investigate alternation (Tolman, 1925). Although the ability to alternate depends on working memory of the previously made choice, the traditional T maze (or Y maze, which is sometimes used for more natural turning angles) is limited in that the encoding period, where the animal must form a memory of the current choice, and the recall period, in which the animal must remember the previous choice, overlap both temporally and spatially. Additionally, because spontaneous alternation is an innate behavior, animals require no learning period to display alternation, making the task un-ideal for studying learning and behavioral acquisition. It also still remains unclear what motivates animals to alternate.
Half a century later, Olton developed a radial arm maze to investigate choice behavior and spatial working memory beyond simple T maze alternation (Olton and Samuelson, 1976; Olton et al., 1979). In the radial maze, animals are expected to visit each arm of the maze once, with no repetitions or revisits. Although this maze requires learning, a trained animal normally visits an arm one time per session (Foreman and Ermakova, 1998), making maze coverage sparse for place cell and electrophysiology experiments. Working memory in the radial maze also incorporates all previous choices during a session, which means memory errors can compound and a single choice is dependent on all previous choices.
Our lab has developed a double-sided T (or H) maze which has several advantages over the traditional T maze and radial mazes. In this task, an animal is forced to an arm on one side T of the maze, and then must choose the same side of the maze on the opposing T in order to get rewarded. While this maze task requires a learning period and thus can be used for studying spatial learning, a trained rat can run dozens of trials a day, each of which requires coverage of at least half of the track. The maze is therefore ideal for use in place cell and other experiments which require robust tract coverage. Furthermore, each choice in the maze requires knowledge of only the immediately preceding navigation, so errors are non-compounding. Finally, this maze is unique in that it temporally and directionally disassociates the memory encoding and retrieval periods, while requiring the same behaviors of the animal during both periods (i.e., both periods require a run down a center stem and then a single turn, which is mirrored across encoding and retrieval). This design allows for independent investigation of brain mechanisms, such as cross-region theta coordination, during memory encoding and retrieval, while at least partially dissociating these stages from behavior.
In this protocol, we will discuss the steps involved in building a low-cost version of this maze for use in rat, as well as the steps necessary for training an animal to become proficient at the task. This maze has been previously used in our laboratory to investigate cell firing, single-region LFP patterns, and cross region LFP coherence in the hippocampus, lateral septum, prefrontal cortex, and ventral tegmental area (Jones and Wilson, 2005a and 2005b; Gomperts et al., 2015; Wirtshafter and Wilson, 2019 and 2020), as well as to investigate the effects of hippocampal theta perturbations on task performance (Siegle and Wilson, 2014).
Materials and Reagents
Animals
Animals used were Long Evans rats. All animals tested were males at about 350-500 g, but females and animals of varying weights could be used. A scaled version of this maze has also been successfully used with mice (Siegle and Wilson, 2014).
Sucrose
Chocolate milk powder, such as Nesquik Chocolate Powder Drink Mix
Reward liquid (see Recipes)
Equipment
For maze
Maze building materials such as ProTRAK 25 2-1/2 in. × 10 ft. 25-Gauge EQ Galvanized Steel Track (Homedepot, model: 250PDT125-15 ). Wood or corrugated plastic also works
Note: If using a metal maze and doing electrophysiology, a grounding wire for the maze.
Black contact paper for water proofing maze, making it less conductive, and increasing contrast with animal for video tracing. We used d-c-fix 26.57 in. × 78.72 in. Black glossy shelf liner (Tmi-Pvc, model: FA3468348 ) secured with TMI Anti-Static Strip and Sheet Plastic (Tmi-Pvc, model: FCA 12060-400 )
Two small reward wells
We used National Hardware 142 Cup Pulls in Antique Brass, ” (Reference #: N335-661 from Amazon.com, USA)
Wood or corrugated plastic to create a block to force the animal to one side at the forced portion of the maze (for an automated version servo controlled doors can be used [Gomperts et al., 2015]).
Risers to elevate the maze, we used blue traffic cones.
For reward delivery
A remote reward delivery system, we used two BrandTechTM BRANDTM seripettorTM Bottletop Dispensers (Fisher Scientific, catalog number: 03-840-010) attached to two common reagent bottles. We ran tubing from the bottles to the reward site in the maze, as described in ‘procedure’. Previous procedures have also used 45 mg food pellets (Gomperts et al., 2015).
For animal tracking
Overhead camera
We used MODEL: BFLY-PGE-09S2C-CS: 0.9 MP, 30 FPS, SONY ICX692, COLOR mounted with Tripod Adapter for BFS (30mm), BFLY, CMLN, CM3, FFMV, FL2, FL3, FMVU, both from https://www.flir.com/.
Appropriate lens for camera depending on maze dimensions and mounting height
We recommend something like Computar H1214FICS-3 CS Mount Lens for the suggested dimensions, at 6ft above the maze.
Tracking software such as Bonsai (https://open-ephys.org/bonsai) or OATE (Newman et al., 2017)
Procedure
Overview of task
The maze is comprised of a forced side, a choice side, and a middle stem. The forced side and choice side each have two arms and contain a forced point and choice point, respectively (Figure 1). On the forced side of the maze, one arm (the arm varies by trial) is blocked off. A trial is initiated when the animal visits the forced point. In order to be rewarded, the animal must visit the arm on the same side of the maze on the choice side of the maze (Figure 2, Video 1). For example, if the animal is forced to the right forced arm, they must also visit the right choice arm to receive a reward. The correct choice must be made on the first try in order to be rewarded. The side the animal is forced to is randomly chosen, with the caveat that the animal can be forced to the same side of the maze for no more than three trials in a row (to avoid the animal thinking only one side of the maze is ever correct). A reward is delivered remotely by an experimenter who is also responsible for moving the blockade that forces the animal to a forced arm. A new trial begins when the animal returns to the forced arm.
Of note, if one seeks to compare neurophysiology associated with choice-associated reward to forced reward, the animal can also be rewarded at the forced side of the maze (Gomperts et al., 2015).
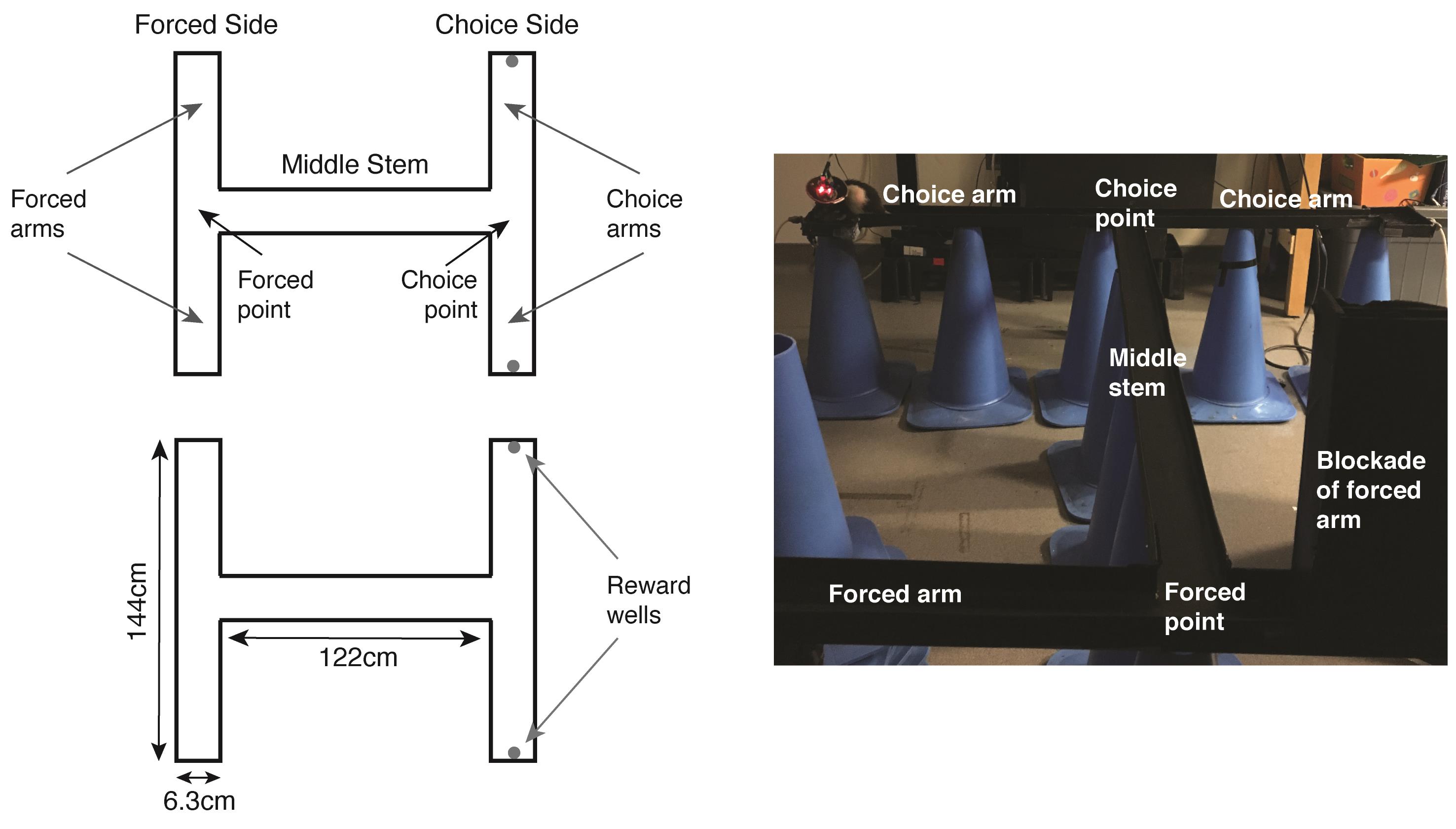
Figure 1. Design of the double-sided T maze. Top left: Schematic showing the maze and different components, as referred to throughout the text. Bottom left: Schematic showing the dimensions of the different maze components. Right: Labeled photograph of the maze.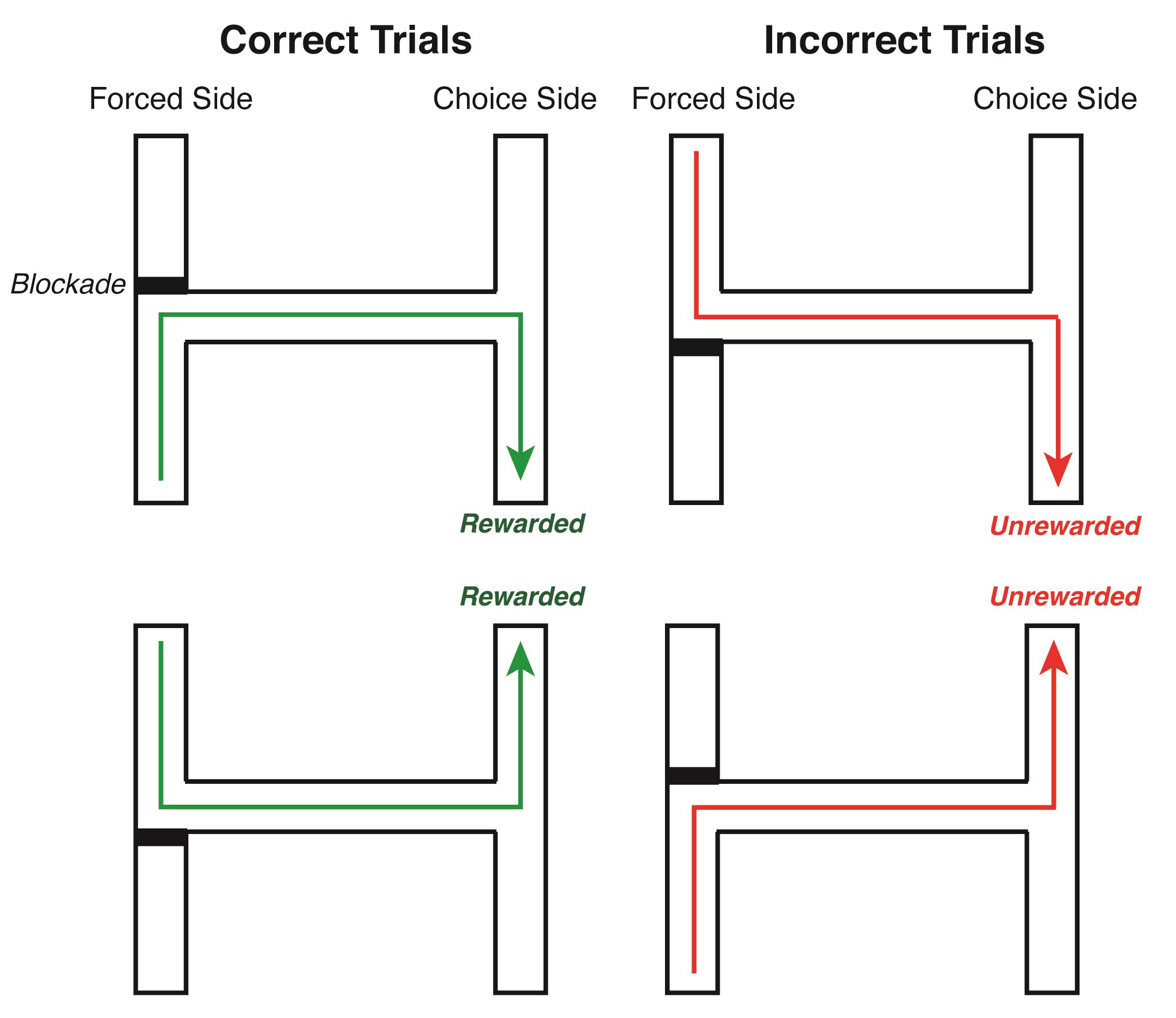
Figure 2. Overview of maze task demands. In the forced choice phase, animals were forced, using a blockade (represented by a shaded black box) to either side of the forced side of the maze. Subsequently, animals had to choose, at the choice side of the maze, the same side of the maze to which they were previously forced. If the animal made the correct choice on their first selection, they were rewarded. Left column: Examples of two correct trials where the animal chose the same choice arm as forced arm. Right column: Examples of two incorrect trials where the animal chose the opposite choice arm to which they were forced. Video 1. Video of a trained rat running two trials on the maze. Video is sped up 2× normal speed. Animal position is indicated with a red circle. The forced side of the maze is on the bottom and the choice side on the top. On the first trial, the animal is forced to the left arm of the forced side. The animal then runs down the center arm and correctly chooses the left arm of the choice side and receives a reward. The animal then returns to the forced side, where he is forced to the right arm. The animal runs down the center stem and incorrectly chooses the left arm and does not receive a reward. The animal then checks the right arm for a reward, which is not administered as the initial choice was incorrect.
Video 1. Video of a trained rat running two trials on the maze. Video is sped up 2× normal speed. Animal position is indicated with a red circle. The forced side of the maze is on the bottom and the choice side on the top. On the first trial, the animal is forced to the left arm of the forced side. The animal then runs down the center arm and correctly chooses the left arm of the choice side and receives a reward. The animal then returns to the forced side, where he is forced to the right arm. The animal runs down the center stem and incorrectly chooses the left arm and does not receive a reward. The animal then checks the right arm for a reward, which is not administered as the initial choice was incorrect.Before beginning
Animal housing
Animals were single housed with enrichment on a 12/12 light dark cycle. Animals were trained during the light cycle as to capture post-training sleep, but could easily be run on the dark cycle. Animals were food deprived to 85-90% of starting weight, with free access to water.
Maze construction
Construct the maze to the parameters in Figure 1. Ends of forced and choice arms can be made slightly larger to allow for turnaround room.
If planning on doing electrophysiology and the maze is constructed of metal, use a conductive wire to ground the maze to a ground source in the room.
We advise covering the maze in black contact paper, which makes for easier cleaning and provides high contrast for animal tracking with overhead cameras.
Construct two blocks the width of the maze (~2.5 in/6.3 cm), by about 6 inches deep and 10 inches tall. These will be used to block off the forced arm during the learning and test phase, as well as the incorrect choice arm during the learning phase. These blocks should be deep and tall enough so that the rat cannot crawl around or over them.
Reward delivery
We recommend using a liquid food reward so the animal cannot travel with the reward; we used 20% chocolate milk powder and 10% sucrose in water. We inexpensively created a remote reward delivery system as follows:
Drill a hole in the wall of the maze at the two reward delivery sites.
Glue or cement a small dish, such as a screw cover cap, beneath the drilled hole.
Feed a pipette tip through the hole so it is over the dish, and connect the pipette tip to tubing. The tubing can then be run to the SeripettorTM Bottletop Dispensers for remote delivery. It is important to fill the length of the tubing with the reward liquid before putting the animal in the maze.
Animal tracking
Install overhead cameras above the maze making sure the entire maze is in the field of view. Adjust tracking software to your desired parameters, which will vary depending on if you are tracking the animal using an LED or not. We adjusted camera parameters using a trial animal to avoid unintended maze exposure with a test animal. Some tracking programs, such as Bonsai, allow you to set the parameters post recording.
Operating the maze
Because the maze is not automated, it requires manual operation. Set up an area of the room where the maze operator can be hidden behind two semi-sheer curtains. The two curtains should part at the forced point of the maze. This setup allows the maze operator to remain hidden from view, while within reach of the object blocking the non-forced arm of the maze to adjust when the animal is at the maze choice arms. This setup also allows the operator the observe the choices made by the animal for manual reward delivery. Please refer to Video 1 for a demonstration on operating the maze.
A reward is dispensed when the animal’s entire body, including tail tip, is entirely in the correct choice arm. While all four feet in the correct arm could be used as a criterion, animals often change or correct their choices with four feet (but not the entire length of their tail) in the maze. Using tail tip as criterion helps eliminate incorrect administration of reward.
Animal training
For an overview of the animal training timeline, see Figure 3.
Handling phase (minimum of 10 days)
Handle the animals for a minimum of 15 min a day for 10 days before placing on the maze. Allow the rat to familiarize themselves to you by holding them in your lap, stroking them lightly, and playing with them, over gradually increasing lengths of time. As the version of the maze we use is not automated, the animal must be familiar with you as to avoid being distracted when you operate the maze. Begin food depriving the animal about a week prior to the start of training the animal on the maze.
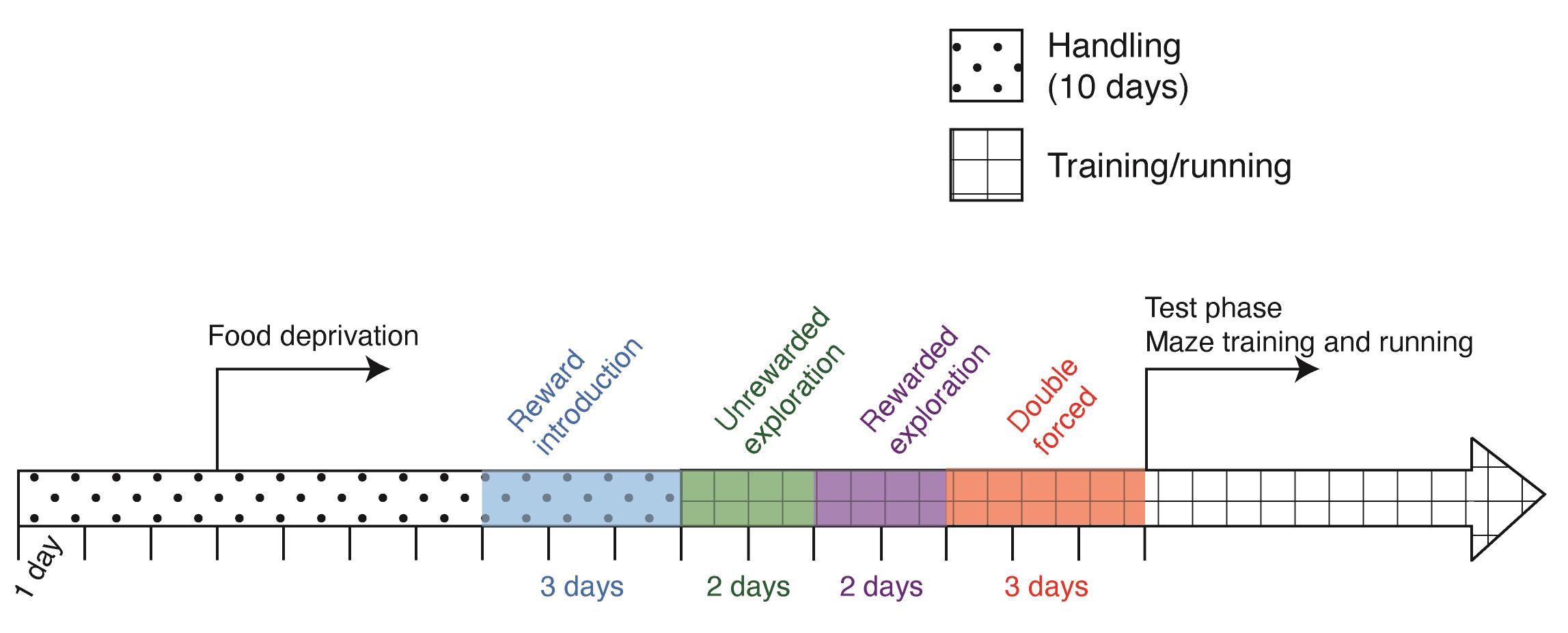
Figure 3. Timeline of maze training. Animals are handled for ten days prior to first exposure to the maze. Three days into handling, food deprivation (to 85% starting weight) begins and is maintained for the duration of all maze running. Three days before the anticipated start of training, the reward mixture should be introduced to the animal in their home cage to familiarize them with the chocolate milk and sucrose mixture. The animal is then trained for 2 days with unrewarded exploration the maze, followed by two days of reward exploration, and 3 days of trials where the animal is double forced (i.e., forced at both the forced and choice sides of the maze to make the correct turns). Following these three training stages, the animal is ready to begin learning the maze task.Familiarizing the animal with the reward (3 days)
Three days before beginning maze exploration, during the animal’s dark/feeding period, leave a small dish in the animal’s home cage with some prepared liquid reward. This is to familiarize the animal with the reward food and to avoid any neophobia on the maze.
Unrewarded exploration phase (2 days)
This phase is designed to get the animal familiar with the track and the surrounding landmarks. This phase should last for two consecutive days and no arms on the maze should be blocked off.
Place the animal on the maze (location was not kept consistent).
Let the animal explore, uninterrupted, for 30 min or until the animal is still for 5 min, whichever comes first.
Remove the animal from the maze.
On the second day, if the entirety of the track was not covered on the first exploration day, be sure to place the animal in the unexplored area when placing them on the track.
Rewarded exploration phase (2 days)
This phase is designed to familiarize the animal with the reward locations on the maze. This phase should last for two consecutive days and begin the day after the end of the unrewarded exploration phase.
Before putting the animal on the track, fill the reward wells with about 0.8 ml of reward each. Set up the remote reward dispensers to dispense 0.8 ml of reward. No maze arms should be blocked off.
Place the animal on the track, at either one of the forced arms or the middle stem.
Allow the animal to explore and find the filled reward wells.
When the animal has finished a reward, remotely dispense 0.5 ml reward into the now empty well after the animal has exited that arm of the maze.
Continue doing this for 30 min or until the animal is still for 5 min, whichever comes first. There may be some initial hesitancy to take the reward on the maze; this is normal.
Double forced learning phase (3 days)
This phase is designed to familiarize the animal with the idea that they will be rewarded on the choice side after visiting the same side of the maze they were at on the maze’s forced side. This phase is easiest to complete with two people; one to move the blockade on each side of the maze.
Before putting the animal on the track, set up the remote reward dispensers to dispense 0.4 ml of reward.
Prepare and make note of the direction the blockade will be on for 30 trials (you will likely only get through 5-12 trials on these days). As stated, the animal will be forced to variable sides of the maze with no more than three consecutive trials forced to the same side. To prepare, either run prepared code that will output trials in this pattern (we used https://github.com/hsw28/behavior/blob/master/maze/leftright.py) or you can assign heads and tails of a coin to left and right and flip a coin. If the coin comes up the same way three times (for example, instructs three times forced right), do not flip for the next trial and assign it to the opposite direction (i.e., left) then resume flipping to designate the next trial.
Block off the designated side of the maze for the first trial on both the reward/choice arms and the forced arms. You will therefore be forcing the animal to the correct side of the maze on the choice side.
Place the animal on the unblocked forced arm
Allow the animal to run to the rewarded arm and receive the reward.
While the animal is taking the reward, set up for the next trial. If the animal is forced the same way, this will require no set up. If the animal is to be forced to the opposite direction, both blockades will need to be moved.
The next trial is considered initiated when the animal has returned to the forced side of the maze (the unblocked arm for the next trial)–you will not be moving the animal yourself. Tail tip in the arm was considered a trial initiation.
Allow the animal to run the next trial with the appropriate sides blocked off according to your plan from step two. Although, at this stage, there is no choice at the choice arm, it is still a good idea to get in the habit of not dispensing a reward until the animal has committed to a choice/reward arm with tail tip in.
Repeat steps 6-8 for 30 trials, 30 min, or until the animal is still for 10 min, whichever comes first. It is common to only get 5-12 trials in on these training days.
Repeat the above steps for a total of three consecutive days.
Test phase (variable length)
This is the final phase of learning and testing. The animal should acquire task proficiency (>75% correct) during this phase, although the time it takes to gain proficiency varies greatly (Figure 5B). We believe a three-day moving average over 75% correct would be an acceptable criteria.
Before putting the animal on the track, set up the remote reward dispensers to dispense 0.4ml of reward.
Prepare and make note of the direction the blockade will be on for 30 trials (see step 2 in the double forced learning phase).
Block off the designated side of the maze for the first trial on the forced side of the maze.
Place the animal on the unblocked forced arm.
Allow the animal to run the maze and select a choice arm.
If the correct choice arm is selected on the first choice, remotely dispense the reward into the reward dish. You can dispense the reward when the animal’s tail tip is in the correct choice arm.
If the animal chooses the incorrect arm, they are not rewarded even if they subsequently visit the correct arm. The animal must initiate a new trial for the chance to be rewarded.
As soon as the animal makes their choice, whether correct or incorrect, setup for the next trial by moving the block on the forced side to the side needed for the next trial, as determined in step 2.
A new trial is considered initiated when the animal returns to the forced side of the maze, with tail tip in the unblocked arm.
Repeat steps 5-9 for 30 trials, 30 min, or until the animal is still for 10 min.
An animal is considered to have learned the task when they complete the task at 75% correct for two consecutive days.
For an example of an animal running two trials on the maze see Video 1.
Data analysis
A tail-tip in the forced arm was the criteria used for the initiation of new trials. A tail tip in the choice arm was used to determine when an animal made a choice on the choice side of the maze. For a representative example, see Figure 5.
Notes
For examples of many of the phenomena explained below see Figure 4.
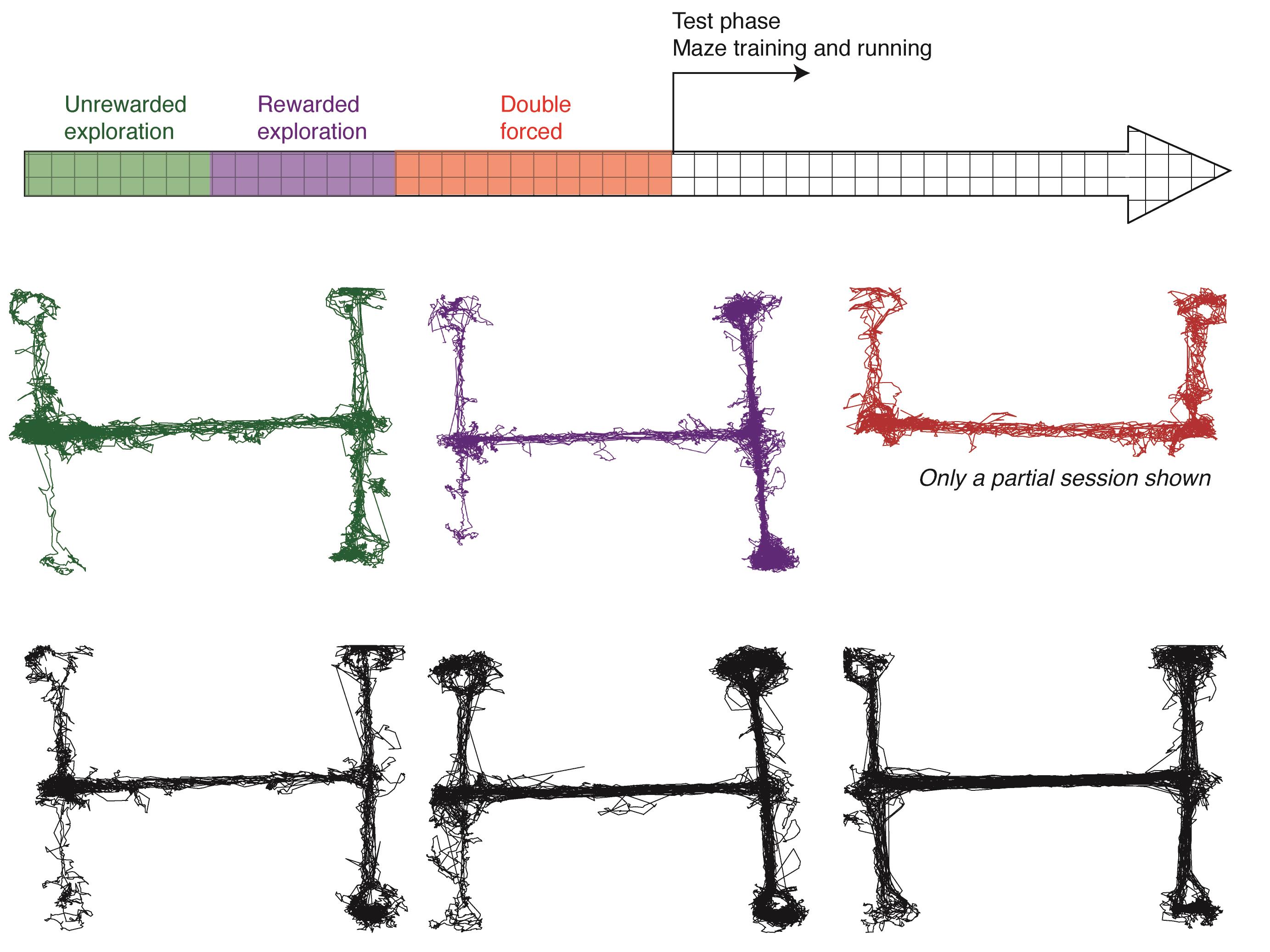
Figure 4. Examples traces of an animal running during different training stages. Colors of traces correlate with training period. Unreward exploration (green): The animal is allowed to freely explore the maze. The animal may not fully cover the maze. This animal only explored the lower forced arm once, so he was placed there on the second day of exploration. Rewarded exploration (purple): The animal is allowed to freely explore the maze with reward in the reward wells. Animals tend to spend the majority of their time during these trials on the choice side of the maze. Double forced (red): Note that only trials forced in one direction are shown here. The animal is forced to make the correct choice at both sides of the maze. Training and running (black): The animal begins training on the complete task. Left: Early training. The animal spends a lot of time on the choice arms of the maze they have associated with reward. The animal has not yet learned they must return to the forced arm to initiate a new trial. Middle: Animal has begun to learn that they must return to the forced side of the maze, but still meanders and is not very focused on running and initiating trials. Right: Animal is well trained. They consistently return to the forced arms and are focused on the task with little wandering or turning mid-arm.During the initial stages of training, the animal will tend to run back and forth between the reward arms. This is normal; it takes time for the animal to learn they have to return to the forced side of the maze. This will likely greatly decrease the number of trials initiated (Figure 5A). For an example, see Video 1.
Animals at the beginning of training will also tend to run halfway up or down the middle arm. A new trial is not considered initiated until the tail tip is in a forced arm, and a new trial should also NOT be started if the animal has not yet visited a choice arm. This will also greatly decrease the number of total trials (Figure 5A).
Even a well-trained animal will often check the other reward arm before returning to the forced side of the maze to initiate a new trial (Note than in some automated variations of this maze, after the animal chooses at the choice side, a door is lowered to prevent the animal from checking the other side of the maze [Gomperts et al., 2015]). For an example, see Video 1.
If an animal perseverates on one side of the maze (incorrectly turns the same way on > 80% of trials) for several days it can be useful to return to the double-forced stage of training for two days. A return to the double-forced stage can also be used if 10 days have passed and the animal is not improving.
At the start of training, many animals are very curious about the blockade on the forced side of the maze; this is normal. However, your animal should NOT be able to climb around or over the blockade. If they are able to, build a taller and/or deeper blockade.
At the start of training, it is normal to get very few trials done in 30 min. This occurs because animals run slowly and spend a lot of time going back and forth between reward arms, rather than initiating new trials by returning to the forced arms. As the animals learn the task and how to initiate new trials, they will become much faster (Figure 5A).
There can be great fluctuations in percent trials correct in one animal. This can be due to natural behavior patterns mirroring trial demands, without the animal actually learning the task. For instance, if your animal has a strong left turn bias and a number of trials require a left turn, it may appear the animal has learned the task when they do not actually understand the task demands. Similarly, if the randomly chosen blocked sides alternate, it can mirror animals’ natural tendency to alternate, but the animals have not actually learned the task (Figure 5B).
We found there to be extensive variability between animals and their ability to learn this task. The fastest animal learned within 5 days and consistently performed at over 95% correct. Most animals took 2-4 weeks and were generally around 80% correct. A small proportion of animals were never able to learn to proficiency (Figure 5B).
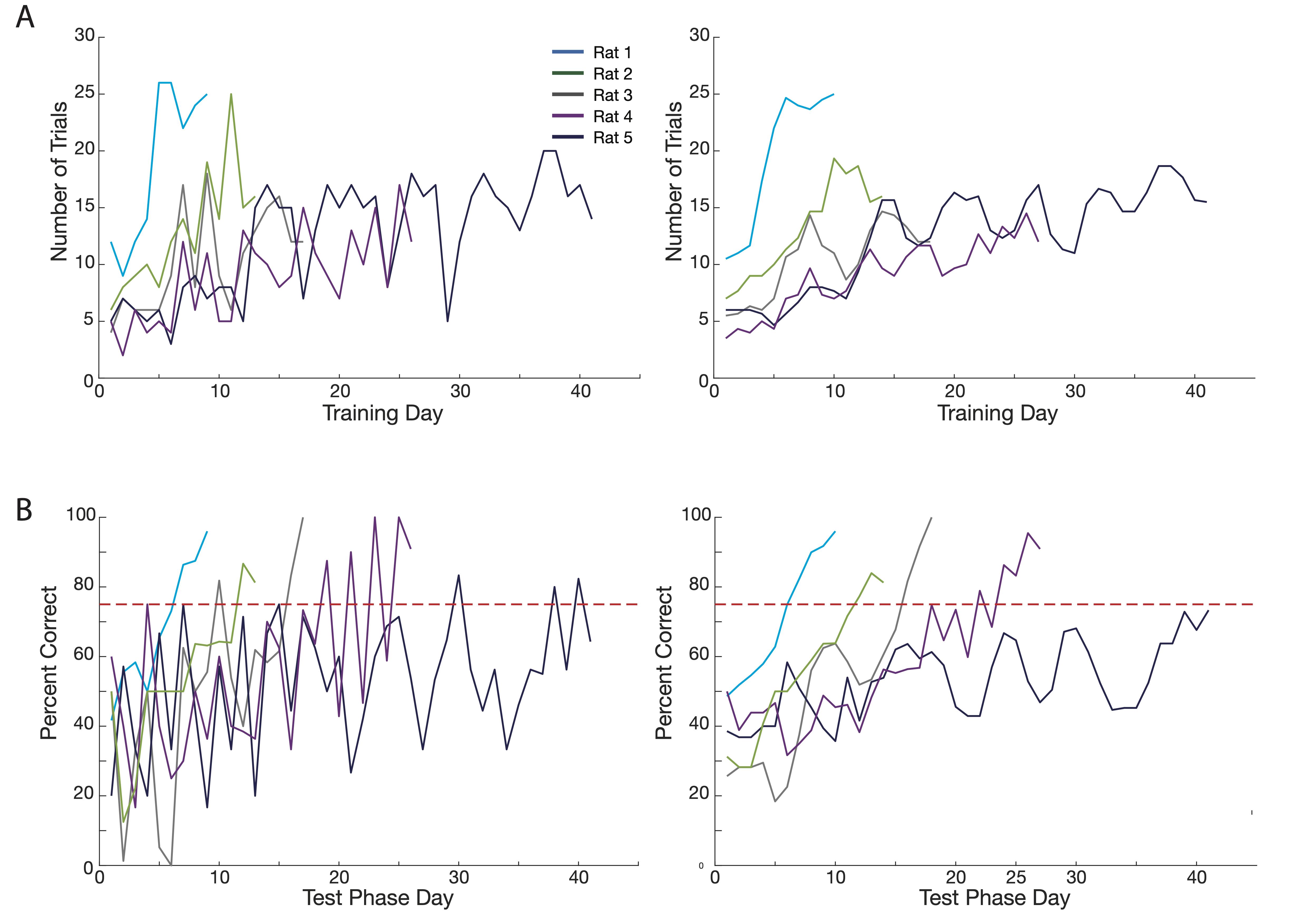
Figure 5. Trials and learning curves of five animals. Note that all five animals were implanted with electrophysiology arrays that may impact learning speed. Graphs begin on the first day of testing (after the double forced period) and continue until animals met criteria (2 consecutive days with 75% or greater accuracy, animals 1-4) or, in the case of animal 5, when the animal was sacrificed. A. Number of trials completed by each animal. As the animals become more proficient at the task, the number of trials initiated and completed in 30 min increases. The number of trials continued upward beyond the animals meeting criteria. Left: All data. Right: Data smoothed with a three-day moving average. B. Accuracy of each animal; animals are the same as in A. 75% correct criteria is marked with a red dotted line. There is high variability in the amount of time it took each animal to reach criteria (from 9 days, to did not reach after 42 days). Left: All data. Right: Data smoothed with a three-day moving average.Be sure not to dispense reward until the animal has committed (tail tip in) to their choice in the choice side of the maze.
Because this non-automated version of the task requires the input of the experimenter, it is important to stereotype your own behavior to avoid serving as a cue in the task. The experimenter who trained the animal should perform the task and avoid wearing any scented products. As noted above, the experimenter should sit behind a curtain when running the animal to avoid any visual cues, and the blockade should be moved only when the animal is at the other side of the track, ideally when they are receiving a reward and distracted. If multiple animals are being run, the track should be cleaned between each animal.
Recipes
Reward liquid
100 g boiling water was mixed with 10 g sucrose and 20 g chocolate milk powder, such as as Nesquik Chocolate Powder Drink Mix, until fully dissolved. Mixture was allowed to cool before use. Mixture was refrigerated between uses and remade weekly.
Acknowledgments
H.S.W. was supported by the Department of Defense (DoD) through the National Defense Science & Engineering Graduate Fellowship (NDSEG) Program. Protocol was adopted from previous works including previous manuscripts from the Wilson lab. We thank Dr Steven Gomperts for his valuable feedback.
Competing interests
There are no competing interests.
Ethics
All procedures were performed within MIT Committee on Animal Care and NIH guidelines under Wilson protocol 0417-037-20, valid from 2017-2020.
References
- Ainge, J. A., Tamosiunaite, M., Woergoetter, F. and Dudchenko, P. A. (2007). Hippocampal CA1 place cells encode intended destination on a maze with multiple choice points. J Neurosci 27(36): 9769-9779.
- Brito, G. N. and Thomas, G. J. (1981). T-maze alternation, response patterning, and septo-hippocampal circuitry in rats. Behav Brain Res 3(3): 319-340.
- Carr, H. (1917). The alternation problem. J Animal Behavior 7(5): 365-384.
- Deacon, R. M. and Rawlins, J. N. (2006). T-maze alternation in the rodent. Nat Protoc 1(1): 7-12.
- Dudchenko, P. A. (2004). An overview of the tasks used to test working memory in rodents. Neurosci Biobehav Rev 28(7): 699-709.
- Foreman, N. and Ermakova, I. (1998). The Radial Arm Maze: Twenty Years On. In: Handbook Of Spatial Research Paradigms And Methodologies. Foreman, N. and Gillett, R. (Eds.). Psychology Press. p. 87-144.
- Fortin, N. J. (2008). Navigation and Episodic-Like Memory in Mammals. In: Learning and memory a comprehensive reference. Byrne, J. H. (Ed.). Academic, London. p. 385-417.
- Gomperts, S. N., Kloosterman, F. and Wilson, M. A. (2015). VTA neurons coordinate with the hippocampal reactivation of spatial experience.Elife 4: e05360.
- Gupta, K., Keller, L. A. and Hasselmo, M. E. (2012). Reduced spiking in entorhinal cortex during the delay period of a cued spatial response task. Learn Mem 19(6): 219-230.
- Hollup, S. A., Molden, S., Donnett, J. G., Moser, M. B. and Moser, E. I. (2001). Accumulation of hippocampal place fields at the goal location in an annular watermaze task. J Neurosci 21(5): 1635-1644.
- Huxter, J. R., Thorpe, C. M., Martin, G. M. and Harley, C. W. (2001). Spatial problem solving and hippocampal place cell firing in rats: control by an internal sense of direction carried across environments. Behav Brain Res 123(1): 37-48.
- Jones, M. W. and Wilson, M. A. (2005a). Phase precession of medial prefrontal cortical activity relative to the hippocampal theta rhythm. Hippocampus 15(7): 867-873.
- Jones, M. W. and Wilson, M. A. (2005b). Theta rhythms coordinate hippocampal-prefrontal interactions in a spatial memory task. PLoS Biol 3(12): e402.
- Kimble, D. P. and Kimble, R. J. (1965). Hippocampectomy and response perseveration in the rat. J Comp Physiol Psychol 60(3): 474-476.
- Lash, L. (1964). Response Discriminability and the Hippocampus. J Comp Physiol Psychol 57: 251-256.
- Newman, J., Hale, G., Myroshnychenko, M., Voigts, J., Flores, F. J., Levy, S. and DonatoRidgley, I. (2017). jonnew/Oat: Oat Version 1.0 (Version 1.0). Zenodo. http://doi.org/10.5281/zenodo.1098579.
- O'Keefe, J. and Nadel, L. (1978). The Hippocampus as a Cognitive Map. Oxford University Press.
- O'Keefe, J. and Speakman, A. (1987). Single unit activity in the rat hippocampus during a spatial memory task. Exp Brain Res 68(1): 1-27.
- Olton, D. S. and Samuelson, R. J. (1976). Remembrance of Places Passed: Spatial Memory in Rats. J Exp Psychol Animal Behavioral Processes 2(2): 97-116.
- Olton, D.S., J.T. Becker, and Handelmann, G. E. (1979). Hippocampus, Space, and Memory. Behavioral Brain Sci 2(3): 313-322.
- Redish, A. D. and Touretzky, D. S. (1998). The role of the hippocampus in solving the Morris water maze. Neural Comput 10(1): 73-111.
- Roberts, W. W., Dember, W. N. and Brodwick, M. (1962). Alternation and exploration in rats with hippocampal lesions. J Comp Physiol Psychol 55: 695-700.
- Siegle, J. H. and Wilson, M. A. (2014). Enhancement of encoding and retrieval functions through theta phase-specific manipulation of hippocampus. Elife 3: e03061.
- Tanila, H., Ku, S., Kloosterman, F. and Wilson, M. A. (2018). Characteristics of CA1 place fields in a complex maze with multiple choice points. Hippocampus 28(2): 81-96.
- Tolman, E. C. (1925). Purpose and cognition: the determiners of animal learning. Psychol Rev 32: 285-97.
- Tolman, E. C. (1948). Cognitive maps in rats and men. Psychol Rev 55(4): 189-208.
- Tolman, E. C., Ritchie, B. F. and Kalish, D. (1946). Studies in spatial learning; place learning versus response learning. J Exp Psychol 36: 221-229.
- Wiener, S. I., Paul, C. A. and Eichenbaum, H. (1989). Spatial and behavioral correlates of hippocampal neuronal activity. J Neurosci 9(8): 2737-2763.
- Wirtshafter, H. S. and Wilson, M. A. (2019). Locomotor and Hippocampal Processing Converge in the Lateral Septum. Curr Biol 29(19): 3177-3192 e3173.
- Wirtshafter, H. S. and Wilson, M. A. (2020). Differences in reward biased spatial representations in the lateral septum and hippocampus. Elife 9: e55252.
Article Information
Copyright
![]() Wirtshafter et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
Wirtshafter et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
How to cite
Readers should cite both the Bio-protocol article and the original research article where this protocol was used:
- Wirtshafter, H. S., Quan, M. and Wilson, M. A. (2021). Dissociating Behavior and Spatial Working Memory Demands Using an H Maze. Bio-protocol 11(5): e3947. DOI: 10.21769/BioProtoc.3947.
- Wirtshafter, H. S. and Wilson, M. A. (2020). Differences in reward biased spatial representations in the lateral septum and hippocampus. Elife 9: e55252.
Category
Neuroscience > Behavioral neuroscience > Cognition
Do you have any questions about this protocol?
Post your question to gather feedback from the community. We will also invite the authors of this article to respond.