- Protocols

- Articles and Issues
- For Authors
- About
- Become a Reviewer

Low-cost and Multiplexable Whole mRNA-Seq Library Preparation Method with Oligo-dT Magnetic Beads for Illumina Sequencing Platforms
Published: Vol 10, Iss 12, Jun 20, 2020 DOI: 10.21769/BioProtoc.3496 Views: 7947
Reviewed by: Amit DeyAnonymous reviewer(s)
Original research article
The authors used this protocol in:

Sep 2017
Advertisement



Protocol Collections
Comprehensive collections of detailed, peer-reviewed protocols focusing on specific topics






Abstract
RNA-Seq is a powerful method for transcriptome analysis used in varied field of biology. Although several commercial products and hand-made protocols enable us to prepare RNA-Seq library from total RNA, their cost are still expensive. Here, we established a low-cost and multiplexable whole mRNA-Seq library preparation method for illumine sequencers. In order to reduce cost, we used cost-effective and robust commercial regents with small reaction volumes. This method is a whole mRNA-Seq, which can be applied even to non-model organisms lacking the transcriptome references. In addition, we designed large number of 3′ PCR primer including 8 nucleotides barcode sequences for multiplexing up to three hundreds samples. To summarize, it is possible with this protocol to prepare 96 directional RNA-Seq libraries from purified total RNA in three days and can be pooled for up to three hundred libraries. This is beneficial for large scale transcriptome analysis in many fields of animals and plant biology.
Keywords: RNA-SeqBackground
In the last decade, sequencing cost has been reduced drastically thanks to the advance in massive parallel sequencing technologies (Muir et al., 2016). On the other hand, the cost at library preparation step stands out. For example, commercial kits for RNA-Seq library preparation such as TruSeq RNA Library Prep Kit (illumine, USA) and NEBNext Ultra RNA Library Prep Kit (NEB, USA) cost around 40-60 dollars per sample. Recently, several studies have developed cost-effective RNA-Seq library preparation methods (Kumar et al., 2012; Nagano et al., 2015; Townsley et al., 2015; Alpern et al., 2019; Kamitani et al., 2019). Particularly, 3′ RNA-Seq protocols (Lasy-Seq and BRB-Seq), enable early-pooling of samples resulting in reducing the cost into about two dollar per sample (Alpern et al., 2019; Kamitani et al., 2019). While 3′ RNA-Seq is economically superior to whole mRNA-Seq method, whole mRNA-Seq can sequence full-length of RNA. Thus, whole mRNA-Seq is good for detection of splicing variants and novel transcripts. Although our previously-developed protocol of whole mRNA-Seq using rRNA depletion is cheap (Nagano et al., 2015), it requires many kinds of antisense oligo against rRNA and enzymes for reverse transcription, 2nd strand synthesis, end-repair, A-tailing, adapter ligation and library amplification. In this protocol, (1) we replaced rRNA depletion against mRNA-purification using oligo-dT beads in order to reduce initial cost. (2) Enzymes required for end-repair to library amplification were replaced with KAPA Hyper Prep Kit (Roche, Switzerland); this simplification increases reaction efficiency as well as reduce labor. (3) We saved reaction volumes throughout all steps (≤ 20 µl), which saves cost and enables handling even with 384-well plates. The required cost is approximately one-third of the golden standard kits. (4) We designed 300 kinds of 3′ PCR primers with barcode sequences for multiplexing, which enabled us to sequence 300 samples at a time with a cost-effective and ultra-high-throughput sequencer such as NovaSeq.
Materials and Reagents
- 0.2 ml PCR tubes
- Pipette tips
- 5× Super Script IV buffer (Invitrogen)
- DTT (Invitrogen)
- Dynabeads® Oligo (dT)25 (Thermo Fisher scientific)
- Total RNA
- Random primer (N)6 (TaKaRa)
- dNTP (25 mM each) (Promega)
- SuperScript IV (Invitrogen)
- Actinomycin D (1,000 ng/μl) (Nacalai Tesque)
- AMPure XP (Beckman Coulter)
- EtOH
- Nuclease-free water
- 10× Blue Buffer (Enzymatics)
- RNase H (Enzymatics)
- DNA polymerase I (Enzymatics)
- KAPA Hyper prep kit (KAPA Biosystems)
- Tris-HCl
- LiCl
- EDTA
- DNA glycosylase (UDG) (Enzymatics)
- KAPA HiFi HotStart ReadyMix (2×) (KAPA Biosystems)
- KAPA Library Quantification Kit Illumina (KAPA Biosystems)
- Agilent High Sensitivity DNA kit (Agilent Technologies)
- 2× binding buffer (see Recipes)
- Washing buffer (see Recipes)
Equipment
- MagnaStand YS-model (FastGene)
- Agilent 2100 Bioanalyzer (Agilent Technologies)
- Quantitative PCR instrument
- Pipette
- Thermal cycler
Procedure
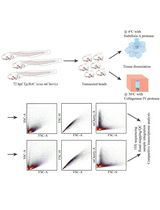
In this protocol, we used MagnaStand YS-model (FastGene) in nucleotide acid purification with magnetic beads. All experiments were conducted in 0.2 ml PCR tubes. Reaction solutions should be mixed by tapping or inversion. All operations should be conducted under a DNA/RNA-free environment. The overview of this protocol is shown in Figure 1.
Figure 1. The protocol flow chart of this protocol. The approximate time required is shown for each step.
- mRNA purification
- Wash 15 μl of Dynabeads® Oligo (dT)25 (Thermo Fisher Scientific) twice each with 50 μl of 2× binding buffer (Recipe 1) using Magna Stand for 0.2 ml PCR Tube (FastGene) and then resuspend the beads in 30 μl of 2× binding buffer for the later use.
‘Wash’ indicates:- Put on a magnet, 5 min, remove supernatant.
- Add 2× binding buffer and mix by pipetting.
- Repeat.
- Denature total RNA (more than 1 μg and RIN > 7.0 is recommended) in 30 μl of distilled water or 10 mM Tris·HCl (pH 8.5) at 65 °C for 2 min and then immediately transfer onto ice. All thermal control procedures in this protocol can be processed in a thermal cycler. Then add 30 μl of the washed Dynabeads® Oligo (dT)25. Mix the mixture well by pipetting and incubate at room temperature for 10 min. And next wash the mixture with 70 μl of washing buffer (Recipe 2) twice using the Magna Stand.
‘Wash’ indicates:- Put on a magnet, 5 min, remove supernatant.
- Add washing buffer and mix by pipetting.
- Repeat.
- Elute the RNA in 30 μl of pre-warmed distilled water at 80 °C for 5 min and then immediately chill on ice. For a second round of polyA-selection, add 30 μl of 2× binding buffer to the solution, and incubate at room temperature for 10 min. Again, wash the mixture with 70 μl of washing buffer twice using the Magna Stand. Elute the RNA in 14 μl of pre-warmed distilled water at 80 °C for 2 min, then immediately place on the magnet and collect into a new tube. The expected volume of the product is 13 μl, with which the following experiments may only be performed twice at most.
- Wash 15 μl of Dynabeads® Oligo (dT)25 (Thermo Fisher Scientific) twice each with 50 μl of 2× binding buffer (Recipe 1) using Magna Stand for 0.2 ml PCR Tube (FastGene) and then resuspend the beads in 30 μl of 2× binding buffer for the later use.
- RNA-seq library preparation and sequencing
- Mix 5 μl of purified mRNA obtained in the above section with 4 μl of 5× Super Script IV buffer (Invitrogen) and 1 μl of frozen stock of 100 mM DTT (Invitrogen).
- mRNA is fragmented by incubating at 94 °C for 4.5 min and then immediately cooled down on ice.
- Then add 0.6 μl of 100 μM random primer (N)6 (TaKaRa) and 0.9 μl of distilled water to the fragmented mRNA. The volume of the mix is 12 μl.
- Incubate the mixture at 50 °C for 5 min and immediately chill on ice to relax the secondary structures of the mRNA.
- Add the reverse transcription master mix (1 μl of frozen stock of 100 mM DTT, 0.4 μl of dNTP (25 mM each) (Promega); 0.1 μl of SuperScript IV (Invitrogen); 0.2 μl of Actinomycin D (1,000 ng/μl) (Nacalai Tesque); and 5.9 μl of distilled water). Now the volume of the mix is 20 μl.
- For the reverse transcription step, incubate the mixture at 25 °C for 10 min, followed by 10 min at 50 °C. Inactivate SuperScript IV by heating the mixture at 80 °C for 15 min. Then add 24 μl of AMPure XP (Beckman Coulter) and 12 μl of 99.5% EtOH, and perform the purification step according to the manufacturer’s manual.
The detail of purification with AMPure XP beads in this protocol is as below:- Mix by pipetting.
- Room temperature, 5 min.
- Put on magnet, 5 min, remove supernatant.
- Add 70 µl of 70% EtOH on the magnet stand and remove it. Repeat this step again.
- Dry up for 1 min.
- Add 10.0 µl or other Nuclease free water, mix by pipetting.
- R.T. for 1 min.
- Put on magnet, collect 10.0 µl or other of supernatant to 384-well PCR plate.
- Elute the transcription product with 10 μl of distilled water. Mix the purified DNA/RNA hybrid solution without beads with the second strand synthesis master mix [2 μl of 10× Blue Buffer (Enzymatics), 1 μl of dUTP/NTP mix (Fermentas), 0.5 μl of frozen stock of 100 mM DTT, 0.5 μl of RNase H (Enzymatics), 1 μl of DNA polymerase I (Enzymatics), and 5 μl of distilled water] The final volume of the mixture is 20 μl.
- Incubate the mixture at 16 °C for 4 h. Purify dsDNA with 24 μl of AMPure XP according to the manufacturer’s manual. Elute the purified dsDNA with 10 μl of distilled water. Use 5 μl of the dsDNA solution for the following step.
- Perform end-repair, A-tailing and adapter ligation using a KAPA Hyper Prep kit (KAPA Biosystems) with 1/10× volume of the solutions according to the manufacturer’s manual. Use 1 μl of 0.1 μM Y-shape adapter (Recipe 3, Nagano et al., 2015) in the adapter ligation step and incubate for 15 min at 20 °C. The final volume of this reaction product is 11 μl.
- Perform size selection of the ligation product with 5.5 μl of AMPure XP, resulting in 0.32× AMPure XP. The first size-selection is conducted at the smaller ratio than the second due to strong viscosity of ligation reaction mix. Elute the purified dsDNA using 10 μl of distilled water. Carry out the second round of size selection with 10 μl of AMPure XP, resulting in 0.5× AMPure XP. Elute the size-selected ligation product with 15 μl of 10 mM Tris-HCl, pH 8.0. Add 1 μl of uracil DNA glycosylase (UDG) (Enzymatics) to the size-selected ligation product. The volume of the mix is 16 μl.
- Incubate the mixture at 37 °C for 30 min to exclude the second-strand DNA.
- For library amplification, mix 2 μl of the UDG-digested DNA with 1 μl of 2.5 μM index primer (CAAGCAGAAGACGGCATACGAGATXXXXXXXXGTGACTGGAGTTCAGACGTGT, XXXXXXXX indicates index sequence in the supplemental file) (Nagano et al., 2015), 1 μl of 10 μM universal primer (AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT) (Nagano et al., 2015), 0.5 μl of distilled water and 5 μl of KAPA HiFi HotStart ReadyMix (2×) (KAPA Biosystems). The volume of the mix is 10 μl.
- Amplify DNA fragments with the adapters and an index sequence using a thermal cycler with the following program: denature at 94 °C for 2 min, 18 cycles at 98 °C for 10 s, 65 °C for 30 s, 72 °C for 30 s as an amplification step, and 72 °C for 5 min for the final extension. Then perform two rounds of size selection to remove adapter dimer with an equal volume of AMPure XP to the library solution with 10 µl of D.W. for elution. Next elute the purified library with 10 μl of distilled water. Now, you can pool the libraries, if needed. Also use library quantification kit (e.g., KAPA Library Quantification Kit Illumina (KAPA Biosystems)) to determine the concentration followed by pooling.
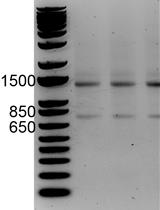
- Take out 1 μl of the purified library for electrophoresis using an Agilent High Sensitivity DNA kit (Agilent Technologies) to evaluate quality. The typical concentration of the library is more than 1 ng/µl, and the size distribution is shown below (Figure 2).

Figure 2. The typical size distribution of the final product of this protocol. A result from electrophoresis produced with Agilent High Sensitivity DNA kit.
Recipes
- 2× binding buffer
40 mM Tris-HCl, pH 7.6
2 M LiCl
4 mM EDTA - Washing buffer
10 mM Tris-HCl, pH 7.6
0.15 M LiCl
1 mM EDTA - Y-shape adapter
A mixture of 100 mM adapters (5′-A*\A*TGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGAT*C*T-3′ 5′-/5Phos/-G*A*TCGGAAGAGCACACGTCTGAACTCCAGTC*A*C-3′.
*signifies a phosphonothioate bond. /5Phos/signifies a phosphorylation) is annealed using a thermal cycler with the following program:
95 °C for 2 min, slow-cooled to 25 °C (0.1 °C/s), followed by 30 min at 25 °C. The annealed adapter (50 μM) is diluted into 0.1 μM with D.W and stored at -20 °C.
Acknowledgments
This work was supported by the JST CREST JPMJCR15O2 to A.J.N. This protocol was modified from the method described in Nagano et al., 2015.
Competing interests
We have no conflicts of interest or competing interests.
References
- Alpern, D., Gardeux, V., Russeil, J., Mangeat, B., Meireles-Filho, A. C. A., Breysse, R., Hacker, D. and Deplancke, B. (2019). BRB-seq: ultra-affordable high-throughput transcriptomics enabled by bulk RNA barcoding and sequencing. Genome Biol 20(1): 71.
- Kamitani, M., Kashima, M., Tezuka, A. and Nagano, A. J. (2019). Lasy-Seq: a high-throughput library preparation method for RNA-Seq and its application in the analysis of plant responses to fluctuating temperatures. Sci Rep 9(1): 7091.
- Kumar, R., Ichihashi, Y., Kimura, S., Chitwood, D. H., Headland, L. R., Peng, J., Maloof, J. N. and Sinha, N. R. (2012). A high-throughput method for Illumina RNA-Seq library preparation. Front Plant Sci 3: 202.
- Muir, P., Li, S., Lou, S., Wang, D., Spakowicz, D. J., Salichos, L., Zhang, J., Weinstock, G. M., Isaacs, F., Rozowsky, J. and Gerstein, M. (2016). The real cost of sequencing: scaling computation to keep pace with data generation. Genome Biol 17: 53.
- Nagano, A. J., Honjo, M. N., Mihara, M., Sato, M. and Kudoh, H. (2015). Detection of plant viruses in natural environments by using RNA-Seq. Methods Mol Biol 1236: 89-98.
- Townsley, B. T., Covington, M. F., Ichihashi, Y., Zumstein, K. and Sinha, N. R. (2015). BrAD-seq: Breath Adapter Directional sequencing: a streamlined, ultra-simple and fast library preparation protocol for strand specific mRNA library construction. Front Plant Sci 6: 366.
Article Information
Copyright
![]() Kashima et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
Kashima et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
How to cite
Readers should cite both the Bio-protocol article and the original research article where this protocol was used:
- Kashima, M., Deguchi, A., Tezuka, A. and Nagano, A. J. (2020). Low-cost and Multiplexable Whole mRNA-Seq Library Preparation Method with Oligo-dT Magnetic Beads for Illumina Sequencing Platforms. Bio-protocol 10(12): e3496. DOI: 10.21769/BioProtoc.3496.
- Ishikawa, T., Kashima, M., Nagano, A. J., Ishikawa-Fujiwara, T., Kamei, Y., Todo, T. and Mori, K. (2017). Unfolded protein response transducer IRE1-mediated signaling independent of XBP1 mRNA splicing is not required for growth and development of medaka fish. eLife 6: e26845.
Category
Systems Biology > Transcriptomics > RNA-seq
Molecular Biology > RNA > RNA sequencing
Do you have any questions about this protocol?
Post your question to gather feedback from the community. We will also invite the authors of this article to respond.