- Protocols

- Articles and Issues
- For Authors
- About
- Become a Reviewer

A Small RNA Isolation and Sequencing Protocol and Its Application to Assay CRISPR RNA Biogenesis in Bacteria

Published: Vol 8, Iss 4, Feb 20, 2018 DOI: 10.21769/BioProtoc.2727 Views: 11025
Reviewed by: David CisnerosKabin XieRamon Cervantes-Rivera
Original research article
The authors used this protocol in:

Aug 2017
Advertisement


Protocol Collections
Comprehensive collections of detailed, peer-reviewed protocols focusing on specific topics







Abstract
Next generation high-throughput sequencing has enabled sensitive and unambiguous analysis of RNA populations in cells. Here, we describe a method for isolation and strand-specific sequencing of small RNA pools from bacteria that can be multiplexed to accommodate multiple biological samples in a single experiment. Small RNAs are isolated by polyacrylamide gel electrophoresis and treated with T4 polynucleotide kinase. This allows for 3’ adapter ligation to CRISPR RNAs, which don’t have pre-existing 3’-OH ends. Pre-adenylated adapters are then ligated using T4 RNA ligase 1 in the absence of ATP and with a high concentration of polyethylene glycol (PEG). The 3’ capture step enables precise determination of the 3’ ends of diverse RNA molecules. Additionally, a random hexamer in the ligated adapter helps control for potential downstream amplification bias. Following reverse-transcription, the cDNA product is circularized and libraries are prepared by PCR. We show that the amplified library need not be visible by gel electrophoresis for efficient sequencing of the desired product. Using this method, we routinely prepare RNA sequencing libraries from minute amounts of purified small RNA. This protocol is tailored to assay for CRISPR RNA biogenesis in bacteria through sequencing of mature CRISPR RNAs, but can be used to sequence diverse classes of small RNAs. We also provide a fully worked example of our data processing pipeline, with instructions for running the provided scripts.
Keywords: CRISPRBackground
Genetic modules associated with Clustered Regularly Interspersed Short Palindromic Repeats (CRISPR) confer adaptive immunity in diverse prokaryotic hosts (Barrangou et al., 2007). Memories of invasive elements (such as viruses, plasmids, and other mobile elements) are stored interspersed between directed repeats of the CRISPR arrays in the host genome in the form of ‘spacers’ comprising the nucleic acid sequence of the molecular parasite (Brouns et al., 2008; Jackson et al., 2017). In order to identify subsequent infections by the same invader, the information contained in CRISPR spacers must be communicated to CRISPR-associated (Cas) endonucleases (Plagens et al., 2015). For the vast majority of CRISPR-Cas systems (phylogenetically grouped as ‘type I’ and ‘type III’ [Makarova et al., 2011 and 2015]), this occurs through the activity of a family of CRISPR-associated endoribonucleases known as Cas6 (Charpentier et al., 2015; Hochstrasser and Doudna, 2015). The entire CRISPR array is transcribed as a precursor CRISPR RNA (pre-crRNA) molecule from the genome, and the Cas6 protein domain helps to process this transcript into a collection of mature CRISPR RNAs (crRNA) consisting of one CRISPR spacer each, flanked by portions of the CRISPR repeat sequence (Carte et al., 2008 and 2010; Haurwitz et al., 2010). This mechanism is known as crRNA biogenesis. Cas6 endoribonucleases promote crRNA biogenesis through site-specific cleavage of the CRISPR repeat sequence, which generates 5’-OH and 2’3’-cyclic phosphate termini (Charpentier et al., 2015; Hochstrasser and Doudna, 2015). Site-specific cleavage at every CRISPR repeat results in the pre-crRNA molecule being chopped at regular intervals into almost equal-length crRNAs, each with a different spacer sequence (Charpentier et al., 2015; Hochstrasser and Doudna, 2015). Mature crRNAs are then loaded onto Cas effector complexes and serve as molecular guides that direct Cas enzymes to target DNA or RNA parasites based on sequence complementarity (Deveau et al., 2008; Marraffini and Sontheimer, 2008). The presence or absence of mature crRNAs isolated from bacterial cell populations can be used as a proxy for Cas6 activity. While biochemical methods have been developed to detect crRNAs (Carte et al., 2008 and 2010; Haurwitz et al., 2010), high-throughput RNA sequencing can be used to assay for Cas6 activity unambiguously (Heidrich et al., 2015). Whole transcriptome sequencing is expensive and can be biased against specific classes of RNAs depending on the specific method of library preparation. Therefore, various small RNA sequencing protocols have been developed to preferentially detect mature crRNAs (Juranek et al., 2012; Richter et al., 2012; Heidrich et al., 2015).
Here, we present a multiplexed small RNA sequencing method to enable facile and reproducible comparisons of crRNA maturation between many different biological conditions at once, such as mutations in the Cas6 protein to assess the mechanism of Cas6 activity. This protocol builds on previous work on small RNA sequencing and ribosome profiling (Lau et al., 2001; Ingolia et al., 2009; Guo et al., 2010; Kwon, 2011; Kivioja et al., 2011). The assay features high sensitivity and dynamic range without expending a lot of sequencing bandwidth on other cellular RNAs, with the caveat that the full-length precursor transcript is not observed by small RNA sequencing.
Materials and Reagents
- Gel-Loading Pipette tips 0.5-200 μl (Thermo Fisher Scientific, InvitrogenTM, catalog number: LC1001 )
- 0.6 ml microcentrifuge tubes (Sigma-Aldrich, catalog number: T5149 )
- Razor blade
- Siliconized 1.5 ml microcentrifuge tubes (VWR, catalog number: 22179-004)
Manufacturer: BIO PLAS, catalog number: 4165SL . - Plastic dish
- Clear plastic film (Saran wrap, or equivalent)
- Corning Costar Spin-X sterile 0.45 μm cellulose acetate centrifuge tube filters (Corning, catalog number: 8162 )
- 0.2 ml PCR tubes, MicroAmp (Thermo Fisher Scientific, Applied BiosystemsTM, catalog number: N8010540 ) or equivalent
- Gel-Excision Pipette tips (Corning, Axygen®, catalog number: TGL-1165-R )
- Heavy Phase Lock Gel in 2 ml tubes (Quantabio, catalog number: 2302830 )
- Corning tube top vacuum filtration system (Corning, catalog number: 430320 )
- Trizol reagent (Thermo Fisher Scietific, InvitrogenTM, catalog number: 15596026 )
- Pre-Cast Novex 6% TBE-Urea polyacrylamide gels (Thermo Fisher Scientific, InvitrogenTM, catalog number: EC6865BOX )
- 10x TBE running buffer (Thermo Fisher Scientific, InvitrogenTM, catalog number: AM9863 )–dilute to 1x before use
- GeneRuler Ultra Low Range DNA Ladder (Thermo Fisher Scientific, Thermo ScientificTM, catalog number: SM1211 )
- 2x formamide gel loading dye (Thermo Fisher Scientific, InvitrogenTM, catalog number: AM8546G )
- SYBR Gold Nucleic Acid Gel Stain (Thermo Fisher Scientific, InvitrogenTM, catalog number: S11494 )
- UltraPure glycogen (Thermo Fisher Scientific, InvitrogenTM, catalog number: 10814010 )
- 200 Proof molecular biology grade ethanol (Sigma-Aldrich, catalog number: E7023 )
- UltraPure DNase/RNase-free distilled water (Thermo Fisher Scientific, catalog number: 10977035 )
- Polynucleotide Kinase (PNK) enzyme and buffer (New England Biolabs, catalog number: M0201S )
- Ammonium acetate solution 7.5 M molecular biology grade (Sigma-Aldrich, catalog number: A2706 )
- 50% PEG 8000 (supplied with NEB T4 RNA ligase I)
- Pre-adenylated 3’ adapter oligo: /5rApp/NNNNNNAGATCGGAAGAGCACACGTCT/3ddC/
- T4 RNA ligase I (New England Biolabs, catalog number: M0204S )
- NEB buffer 2 (New England Biolabs, catalog number: B7002S )
- 5’ Deadenylase (New England Biolabs, catalog number: M0331S )
- RecJf (New England Biolabs, catalog number: M0264S )
- Acidified phenol:chloroform 1:1 mixture (Thermo Fisher Scientific, catalog number: AM9720 )
- Chloroform (Sigma-Aldrich, catalog number: 496189 )
- 5x First Strand Buffer (supplied with SuperScript II Reverse Transcriptase)
- 0.1 M dithiothreitol (supplied with SuperScript II Reverse Transcriptase)
- 10 mM dNTP mix (Thermo Fisher Scientific, Thermo ScientificTM, catalog number: R0191 )
- SuperScript II Reverse Transcriptase (Thermo Fisher Scientific, InvitrogenTM, catalog number: 18064014 )
- Reverse transcription primer:
/5Phos/AGATCGGAAGAGCGTCGTGT/iSp18/CACTCA/iSp18/GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCT - Pre-Cast Novex 10% TBE-Urea polyacrylamide gels (Thermo Fisher Scientific, InvitrogenTM, catalog number: EC6875BOX )
- 1 N sodium hydroxide solution (Merck, catalog number: SX0607H )
- CircLigase ssDNA ligase and 10x reaction buffer (Lucigen, catalog number: CL4111K )
- 1 mM ATP solution (supplied with circLigase)
- UltraPure Agarose (Thermo Fisher Scientific, InvitrogenTM, catalog number: 16500500 )
- 10x TAE (Thermo Fisher Scientific, catalog number: AM9869 )–dilute to 1x before use
- Ethidium bromide solution 10 mg/ml (Thermo Fisher Scientific, Thermo ScientificTM, catalog number: 17898 )
- Phusion High-Fidelity PCR master mix (Thermo Fisher Scientific, Thermo ScientificTM, catalog number: F531S )
- Indexing primers:
CAAGCAGAAGACGGCATACGAGATXXXXXXGTGACTGGAGTTCAGACGTGTGCTCTTCCG where the X6 barcodes correspond to Illumina TruSeq LT indexes AD001 to AD008 [ATCACG, CGATGT, TTAGGC, TGACCA, ACAGTG, GCCAAT, CAGATC, ACTTGA]
Note: More indexing primers may be added as needed. - Universal PCR primer:
AATGATACGGCGACCACCGAGATCTACACTCTTTCCCTACACGACGCTCTTCCGATCT - DNA gel loading dye 6x (Thermo Fisher Scientific, Thermo ScientificTM, catalog number: R0611 )
- 25 bp DNA ladder
- MinElute Gel extraction kit (QIAGEN, catalog number: 28604 )
- 5 M sodium chloride solution BioUltra for molecular biology (Sigma-Aldrich, catalog number: 71386 )
- 0.1 M EDTA solution, pH 7.5 (Merck, catalog number: EX0546A )
- 1 M HEPES solution BioPerformance certified and 0.2 μm filtered (Sigma-Aldrich, catalog number: H3537 )
- 8 N potassium hydroxide solution (Sigma-Aldrich, catalog number: P4494 )
- 50 mM manganese chloride solution (supplied with circLigase)
- Qubit dsDNA HS Assay Kit (Thermo Fisher Scientific, InvitrogenTM, catalog number: Q32854 )
- 1 M Dithiothreitol solution BioUltra for molecular biology (Sigma-Aldrich, catalog number: 43816 )
- Glycerol for molecular biology (Sigma-Aldrich, catalog number: G5516 )
- 1 M magnesium chloride solution for molecular biology (Sigma-Aldrich, catalog number: M1028 )
- 20 mg/ml Acetylated bovine serum albumin (Thermo Fisher Scientific, catalog number: AM2614 )
- Polyacrylamide gel elution buffer (see Recipes)
- 1 M HEPES/KOH buffer pH 8.3 (see Recipes)
- 60% glycerol solution (see Recipes)
- 5x adenylation buffer (see Recipes)
Equipment
- Scissors
- XCell SureLock Mini-Cell (Thermo Fisher Scientific, InvitrogenTM, model: XCell SureLockTM Mini-Cell, catalog number: EI0001 )
- Heated-lid thermocycler, Veriti 96-well (Thermo Fisher Scientific, Applied BiosystemsTM, model: VeritiTM 96-well, catalog number: 4375786 ) or equivalent
- Transilluminator with 365 nm wavelength UV bulb (VWR, catalog number: 89131-464 or equivalent)
- Tabletop microcentrifuge (Eppendorf, model: 5424 or equivalent, for use at room temperature and 4 °C)
- Freezer capable of reaching -80 °C
- Programmable water bath/heat block
- Rotisserie tube rotator (VWR, catalog number: 10136-084 or equivalent)
- 10 μl pipette
- Gel electrophoresis power supply (Thermo Fisher Scientific, model: OwlTM EC1000XL or equivalent)
- Owl EasyCast Mini Gel electrophoresis system (Thermo Fisher Scientific, Thermo ScientificTM, model: OwlTM EasyCastTM B2 ) or equivalent
- 100-1,000 μl pipette
- Qubit 3.0 Fluorometer (Thermo Fisher Scientific, InvitrogenTM, model: QubitTM 3 , catalog number: Q33216)
Procedure
Duration: The protocol can be performed comfortably in 4 days (including RNA isolation from bacteria) as follows: Steps A1-A16 on day 1, A17-C5 on day 2, D1-E12 on day 3, and E13 onwards on day 4. The flowchart below summarizes the major steps in the protocol (Figure 1).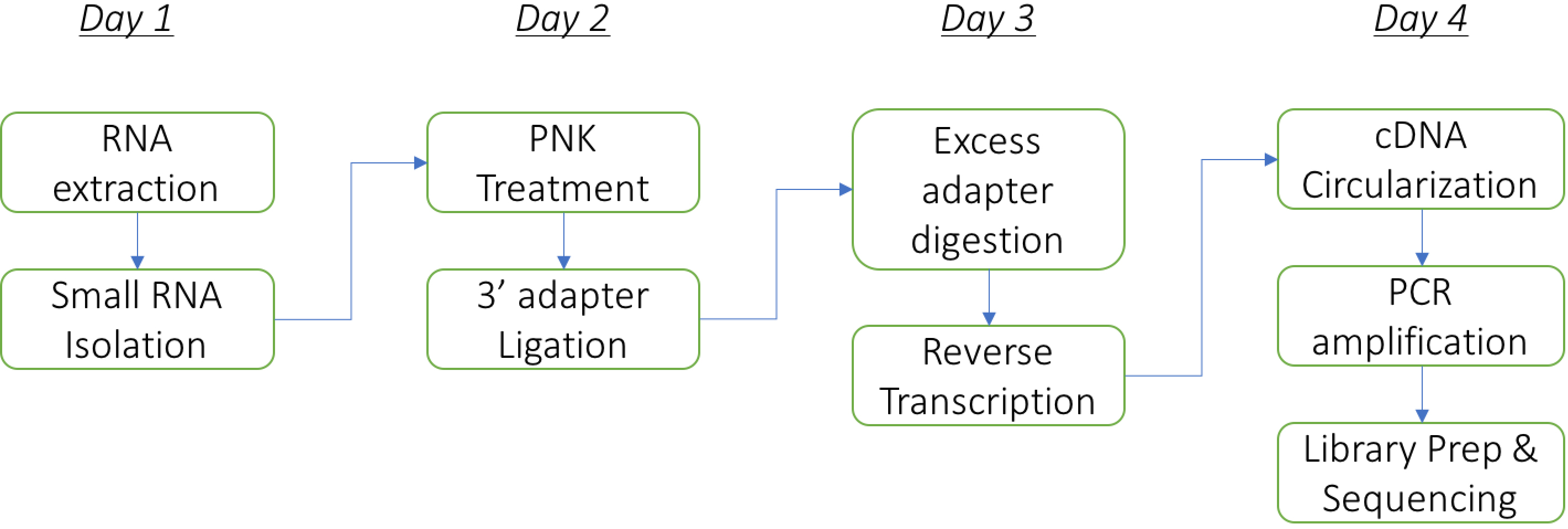
Figure 1. The flowchart of the major steps in the protocol
RNA isolation from bacteria: RNA extraction methods will depend on the bacteria under study. The extraction method must avoid any column-based or size-dependent purification steps that could lead to preferential loss of small RNAs. We follow the manufacturer’s instructions provided with Trizol reagent for our model system Marinomonas mediterranea, a gamma-proteobacterium (like E. coli). We use no more than 200-500 μl of saturated M. mediterranea culture in Marine Broth 2216 for RNA isolation.
Sequencing library preparation:
- Small RNA isolation by denaturing polyacrylamide gel electrophoresis (PAGE)
- Assemble a pre-cast Novex 6% TBE-Urea denaturing polyacrylamide gel in the XCell SureLock Mini-Cell Electrophoresis System.
Note: Remember to remove the gel comb and the green tape at the bottom of the gel cassette before assembling the electrophoresis cell. - Fill the inside and outside chambers with 1x TBE running buffer, and pre-run the gel at 180 V for at least 30 min.
- Prepare samples of at least 5-10 μg total intact RNA and 0.1 μg Ultra Low Range DNA ladder in 2x formamide gel loading dye at a final concentration of 1x. We suggest keeping the total volume of each sample < 15 μl.
- Denature the samples and ladder by heating in a thermocycler with a pre-heated lid at 94 °C for 5 min, then immediately place in an ice-water slurry.
- While the samples are denaturing, thoroughly flush urea out of each gel well using a 100 μl pipette with the running buffer from the inner chamber several times.
- Load samples carefully with gel-loading pipette tips.
Note: Leave 1-2 lanes between different RNA samples to reduce the amount of cross-contamination between experiments. We recommend including no more than 4-5 RNA samples (and one lane for the approximate sizing ladder) in a 10-lane gel. - Run at 180 V until the bromophenol blue dye front (bottom band ~25 nt) reaches close to the end of the gel (about 35 min).
- While the gel is running, prepare gel elution tubes by making a small cross-shaped incision at the bottom of a 0.6 ml tube with a clean razor blade (see diagram for details) and placing it inside a 1.5 ml siliconized centrifuge tube. Do not remove the caps of either the 0.6 ml or 1.5 ml tubes (Figure 2).
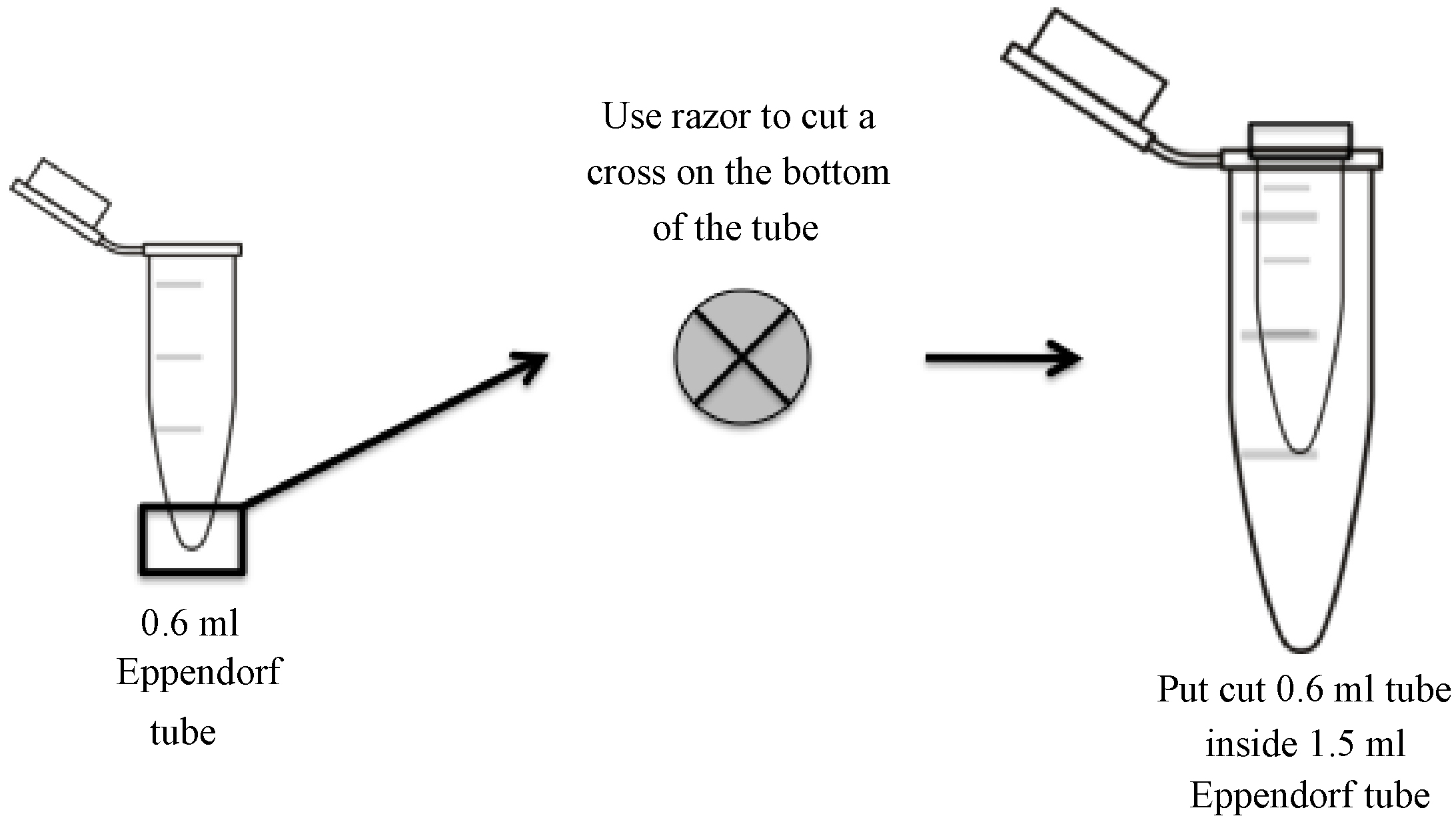
Figure 2. Longitudinal and transverse view of 0.6 ml tube for pulverizing polyacrylamide gel fragments. A cross-shaped incision is made at the bottom of 0.6 ml centrifuge tube using a clean razor blade. The polyacrylamide gel fragment is pulverized as it is forced through the incision and into a 1.5 ml siliconized centrifuge tube by centrifugation.
Note: Use of siliconized tubes is critical to avoid the loss of RNA due to non-specific binding to tube walls. - Carefully disassemble the cassette and remove the gel. Stain with SYBR Gold diluted 1:5,000 in 1x TBE running buffer.
Note: We typically use 3 μl of SYBR Gold in 15 ml running buffer and stain on a slowly rocking nutator in a small plastic dish for about 5 min at room temperature. Wear appropriate protective equipment to prevent exposure to SYBR Gold, and also to prevent contamination of samples with extraneous biological material. - Transfer the gel onto a clear plastic film and place on a UV transilluminator (set at 365 nm wavelength).
- Carefully excise out gel fragments for each sample from the 25-nt marker upto the 75-nt marker, which should be just below a bright band corresponding to cellular tRNAs (Figure 3).
Note: For a non-degraded RNA sample, there will most likely be no visible RNA in the excised gel fragment. We often include a small portion of the lowest visible tRNA band to serve as a carrier in subsequent steps. Intact tRNAs typically do not reverse transcribe efficiently and should not result in overwhelming contamination in the final dataset.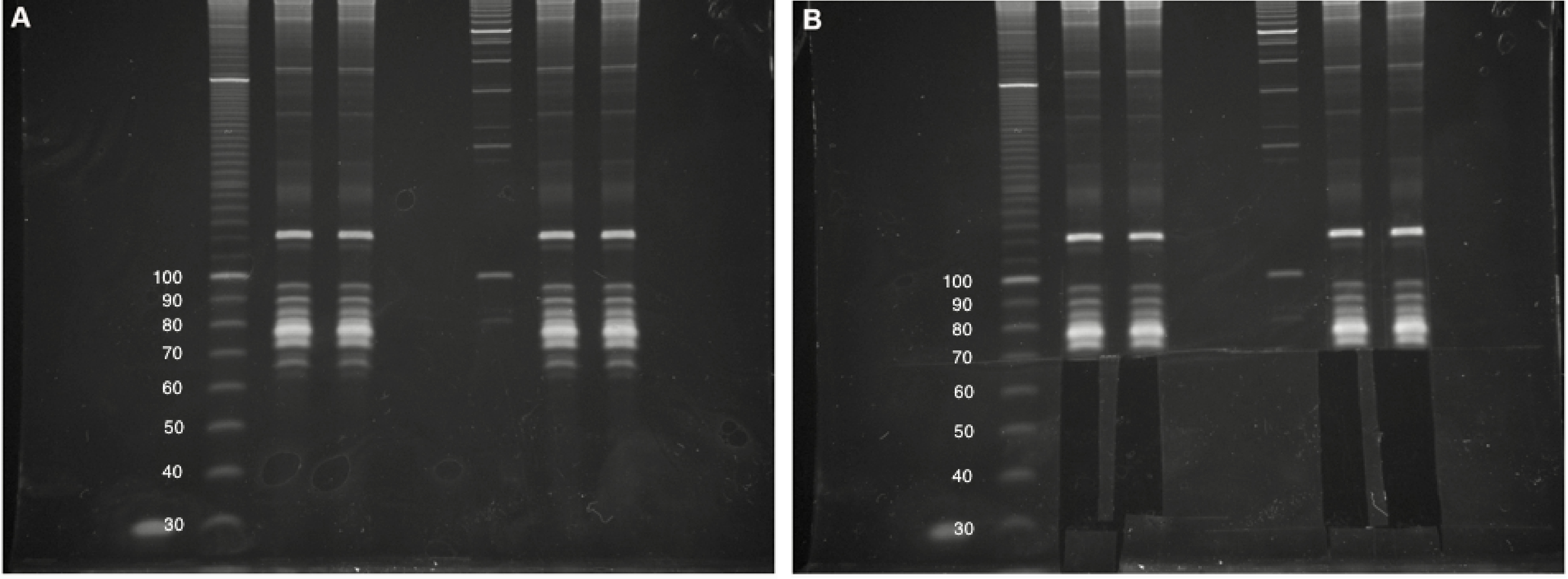
Figure 3. Small RNA size selection. A. Four intact total RNA samples (6% denaturing TBE-Urea PAGE). Two biological replicates for each experiment were run side-by-side, with approximate DNA sizing ladders. Images cropped and brightness/contrast adjusted in Microsoft Word. B. Size selection of 25- to 75-nt RNAs, including lowest tRNA band. The Invitrogen 10 bp DNA ladder was used in this gel but has since been discontinued by the manufacturer. - Place each gel fragment in a separate elution tube.
- Centrifuge each elution tube at 20,000 x g at room temperature in a tabletop microcentrifuge for 1-3 min to force the gel fragment through the incision in the 0.6 ml tube and into the 1.5 ml siliconized tube. Carefully remove any leftover gel pieces in the 0.6 ml tube with a clean pipette tip, and place in the corresponding 1.5 ml siliconized tube. Discard the 0.6 ml tube.
- Add 300 μl of polyacrylamide gel elution buffer (see Recipes) into each 1.5 ml siliconized tube containing pulverized gel fragments, and vortex vigorously to make a uniform slurry.
- Place the tubes at -80 °C to freeze, then in a 37 °C water bath for 2 min to thaw. Vortex vigorously, and then repeat this step 2-3 times.
- Place the samples on ice for 1 min to cool, then incubate at 4 °C with shaking in a rotisserie tube rotator overnight to elute RNA from gel fragments.
- Centrifuge briefly to collect gel slurry at the bottom of the tube.
- Prepare filtration tubes by placing 0.45 μm sterile cellulose acetate filters in new 1.5 ml siliconized tubes.
- Widen the bore of 1,000 μl pipette tips using clean scissors, and transfer gel slurry to the filtration tubes.
- Collect RNA eluate by centrifugation at 16,000 x g for 2 min at room temperature, discard the filters, and add (in order) 1 μl (20 mg/ml) glycogen and 1 ml 100% ethanol to each sample.
- Precipitate nucleic acids by placing the tubes at -80 °C for 30 min.
- Centrifuge at 20,000 x g at 4 °C for 30 min, and discard the ethanol while taking care not to dislodge the pellet.
- Wash with 1 ml freshly prepared 70% ethanol, taking care to flush out the cap by inverting several times.
Note: It is not necessary to vortex aggressively at this step. Vortexing can be helpful in dislodging the pellet, but excessive agitation, as well as use of more concentrated ethanol for washing will lead to pellet fragmentation and reduction in yield. - Centrifuge at 20,000 x g for 2 min at room temperature to collect the pellet, pour off the ethanol and repeat the wash.
- Centrifuge briefly at room temperature to collect residual ethanol after the second wash step is complete. Remove remaining ethanol using a 10 μl pipette, taking care not to touch the pellet. Air dry for 3 min.
Note: After removing residual ethanol with a pipette, 3 min is sufficient to dry the pellet. We typically dry under a flame to prevent dust from accidentally settling in the tubes. - Resuspend pellet in 17 μl RNase-free water at room temperature.
Note: The added glycogen from Step A20 should result in a clearly visible pellet that may become translucent upon drying. The pellet will be easy to resuspend provided it has not been over-dried.
- Assemble a pre-cast Novex 6% TBE-Urea denaturing polyacrylamide gel in the XCell SureLock Mini-Cell Electrophoresis System.
- Polynucleotide kinase (PNK) treatment
- Denature RNA at 90 °C for 1 min in a heated-lid thermocycler, then plunge in ice for 1 min.
Note: We use the entire RNA sample from the previous step, and do not attempt to measure its concentration since the amount of RNA is often below the detection limit of commercial assay kits. - To 17 μl of the RNA sample, add (in order) 2 μl 10x PNK buffer and 1 μl PNK enzyme, and mix well by pipetting.
- Incubate at 37 °C for 1 h.
- Add (in order) 80 μl RNase-free water, 50 μl (7.5 M) ammonium acetate, and 500 μl 100% ethanol.
- Precipitate RNA as in Steps A21-A25.
- Resuspend pellet in 4.5 μl RNase-free water at room temperature.
Note: The added glycogen from Step A20 should result in a clearly visible pellet that may become translucent upon drying. The pellet will be easy to resuspend provided it has not been over-dried.
- Denature RNA at 90 °C for 1 min in a heated-lid thermocycler, then plunge in ice for 1 min.
- 3’ adapter ligation (without ATP)
- Pre-mix equal volumes of 5x adenylation buffer (see Recipes) and 50% PEG 8000 to make 4 μl mixture per sample (+ 20% extra to account for pipetting error).
- Transfer RNA samples to 0.2 ml PCR tubes, and add 4 μl of the mixture to each RNA sample. Mix well by pipetting.
Note: PEG 8000 is viscous and pre-mixing with 5x adenylation buffer helps to reduce viscosity and make dispensing to sample tubes easier. Mix by pipetting for as long as necessary until the solution appears uniform. - Heat sample to 98 °C for 1 min, plunge in ice for 1 min, then place at room temperature for the next step.
- Add (in order) 0.5 μl (100 μM) pre-adenylated 3’ adapter oligo, and 1 μl T4 RNA ligase I. Mix well by pipetting.
Note: We keep the pre-adenylated 3’ adapter oligo at -80 °C and thaw on ice before use. - Incubate in a thermocycler at 22 °C for 6 h. The reaction can be stored at 4 °C if performing this step overnight.
- Pre-mix equal volumes of 5x adenylation buffer (see Recipes) and 50% PEG 8000 to make 4 μl mixture per sample (+ 20% extra to account for pipetting error).
- Excess adapter digestion
- Pre-mix 78 μl RNase-free water and 10 μl NEB buffer 2 for each sample.
- Incubate RNA samples at 95 °C for 1 min, allow to cool and then add 88 μl of buffer mixture.
- Add 1 μl 5’ deadenylase, mix, and incubate at 30 °C in a thermocycler for 30 min.
- Add 1 μl RecJf, mix, and incubate at 37 °C in a thermocycler for 30 min.
Note: The 5’ deadenylase removes the /5rApp/ group from the free 5’ ends of un-ligated pre-adenylated adapters, thereby exposing the excess adapter molecules to digestion by the single-stranded-DNA-specific 5’ → 3’ exonuclease RecJf. - During the digestion step, pre-spin a heavy phaselock gel tube for each sample at 16,000 x g for 2 min at room temperature.
- Add 100 μl RNase-free water to each RNA sample, mix well, and transfer to a pre-spun phaselock tube.
- Add 200 μl acid-phenol:chloroform to each sample and mix by shaking vigorously by hand.
- Centrifuge at 16,000 x g at room temperature for 5 min.
- Add 200 μl chloroform to each sample in the same tube and mix gently by inversion.
- Centrifuge at 16,000 x g at room temperature for 5 min.
- Transfer the aqueous phase to a new 1.5 ml siliconized tube, and add (in order) 0.5 μl (20 mg/ml) glycogen, 100 μl (7.5 M) ammonium acetate and 1 ml 100% ethanol to each sample.
- Precipitate RNA as in Steps A21-A25.
- Resuspend pellet in 5.75 μl RNase-free water at room temperature.
Note: The added glycogen from Step D11 should result in a clearly visible pellet that may become translucent upon drying. The pellet will be easy to resuspend provided it has not been over-dried.
- Pre-mix 78 μl RNase-free water and 10 μl NEB buffer 2 for each sample.
- Reverse-transcription
- Prepare a reverse-transcription master mix, with 2 μl 5x First-strand buffer, 1 μl (0.1 M) dithiothreitol, and 0.5 μl (10 mM) dNTPs for each RNA sample (+ 20% extra to account for pipetting error).
- Transfer RNA samples to 0.2 ml PCR tubes, and add 0.25 μl (100 μM) reverse-transcription primer to each tube.
- Heat samples to 90 °C for 1 min, then plunge on ice for 1 min.
- Add 3.5 μl of reverse-transcription master mix to each sample.
Note: Also maintain a ‘no-template’ control, which will allow for visualization of the reverse-transcription primer during the subsequent gel purification step. - Add 0.5 μl SuperScript II reverse transcriptase to each reaction and mix well by pipetting.
- Incubate at 42 °C for 30 min in a heated-lid thermocycler to synthesize complementary DNA (cDNA).
- During this incubation step, set up and pre-run a Novex 10% TBE-Urea denaturing polyacrylamide gel in the XCell SureLock Mini-Cell Electrophoresis System at 180 V for at least 30 min as described in Steps A1-A2.
- Add 2 μl (1 N) sodium hydroxide to each reaction.
- Incubate at 70 °C for 15 min in a heated-lid thermocycler to hydrolyze RNA.
- Add 12 μl 2x formamide gel loading dye (i.e., at a final concentration of 1x) to each sample.
- Prepare 0.1 μg of Ultra Low Range DNA ladder in 2x formamide gel loading dye at a final concentration of 1x.
- Denature and run cDNA on pre-run gels as in Steps A4-A25, with the following modifications:
- In Step A7, run the gel until the Xylene Cyanol dye front (top band ~55 nt) reaches close to the bottom of the gel (about 45-60 min).
- In Step A11, excise gel fragments in the 100- to 160-nt range (processed CRISPR RNAs are generally in the ~50-100-nt range and the reverse transcription primer adds ~65-nt to the size of the desired small RNAs). Use the no-template control as a visual guide during gel excision, and avoid the bright bands formed in this lane (typically no higher than 90-nt) (Figure 4).
- In step A16, cDNA elution should be carried out at room temperature.
- In Step A7, run the gel until the Xylene Cyanol dye front (top band ~55 nt) reaches close to the bottom of the gel (about 45-60 min).
- Resuspend the cDNA pellet in 17 μl water. Reserve half the sample and store at -20 °C as a backup.
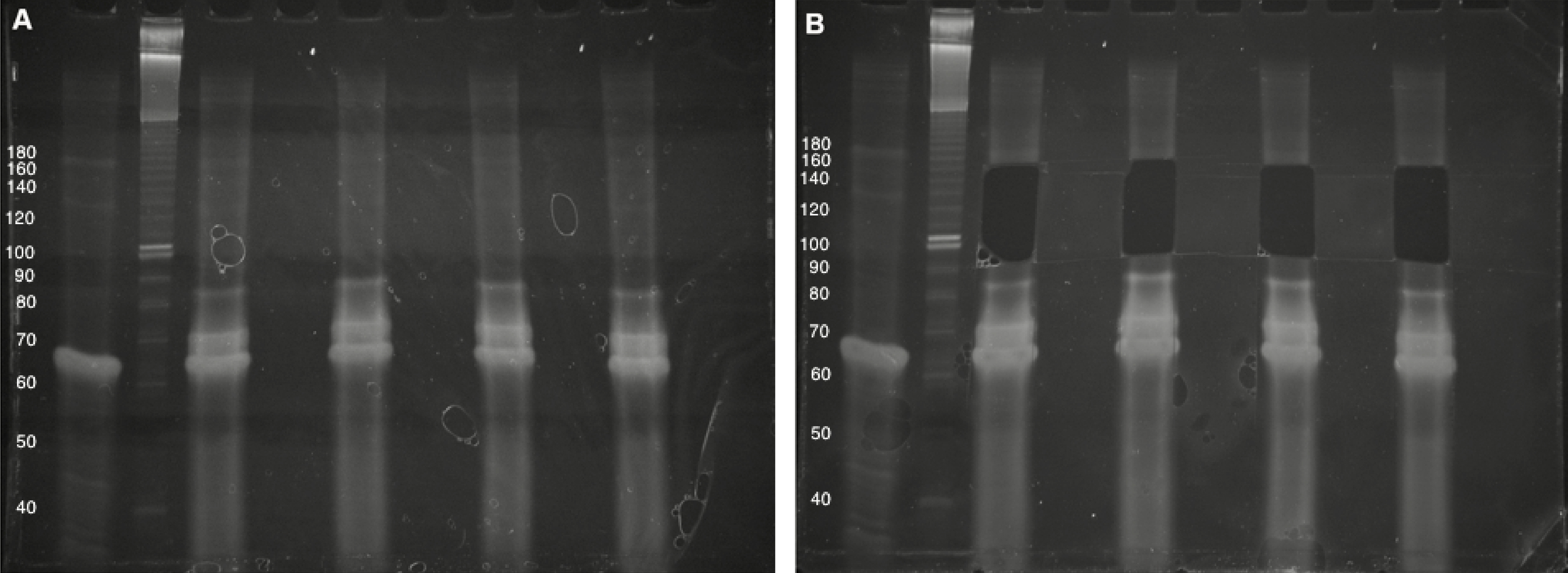
Figure 4. Purification of cDNA following reverse transcription. A. Four cDNA sample (10% denaturing TBE-Urea PAGE). The first lane is the no-template control, followed by an approximate DNA sizing ladder. Brightness/contrast adjusted in Microsoft Word. B. Size selection of 100- to 160-nt cDNAs, avoiding bright high-molecular-weight bands. The Invitrogen 10 bp DNA ladder was used in this gel but has since been discontinued by the manufacturer.
- Prepare a reverse-transcription master mix, with 2 μl 5x First-strand buffer, 1 μl (0.1 M) dithiothreitol, and 0.5 μl (10 mM) dNTPs for each RNA sample (+ 20% extra to account for pipetting error).
- cDNA circularization
- Add 1 μl 10x circLigase reaction buffer, 0.5 μl (1 mM) ATP, and 0.5 μl (50 mM) manganese chloride solution to 8 μl cDNA in 0.2 ml PCR tubes.
- Add 0.5 μl circLigase enzyme. Mix well by pipetting.
- Incubate at 60 °C for 75 min in a heated-lid thermocycler.
- While the circularization reaction is proceeding, prepare enough 3-3.5% agarose gels (in 1x TAE with 0.5 μg/ml ethidium bromide) to accommodate 5 PCR lanes plus 1 DNA sizing ladder per cDNA sample.
Note: We use the 1.5 mm thick 12-well combs supplied with Owl EasyCast B2 gel electrophoresis systems to make enough lanes for two cDNA samples. - Stop the reaction by heating to 80 °C for 15 min. Use this circularized cDNA (ccDNA) sample directly as a template for PCR.
- Add 1 μl 10x circLigase reaction buffer, 0.5 μl (1 mM) ATP, and 0.5 μl (50 mM) manganese chloride solution to 8 μl cDNA in 0.2 ml PCR tubes.
- PCR amplification and purification of sequencing libraries
- Prepare a PCR mix with 100 μl 2x Phusion Master Mix, 1 μl (100 μM) Universal PCR primer, and 100 μl water for each cDNA sample.
- Add 200 μl PCR mix to 5 μl ccDNA from Step F5. Add 1 μl of a different indexing primer for each sample.
- Split each reaction mixture into 5 separate 0.2 ml PCR tubes (40 μl each).
- Perform a PCR titration for each ccDNA sample by running each sub-reaction for a different number of cycles according to the following program:
- 98 °C for 30 sec
- N cycles of
98 °C for 10 sec
60 °C for 10 sec
72 °C for 10 sec - hold at 10 °C
- 98 °C for 30 sec
- Add 8 μl of 6x DNA gel loading dye to each reaction.
- Load all 5 titrations for each sample side-by-side on the agarose gel. We suggest using the Ultra Low Range DNA ladder (~0.5 μg/lane) to demarcate sets of titrations of different ccDNA samples.
- Run the gel in agarose gel running buffer (1x TAE with 0.5 μg/ml ethidium bromide) at 3.6-3.7 V/cm for 1-2 h.
- Place the gels on a UV transilluminator (set at 365 nm wavelength). Choose the appropriate number of PCR cycles for each ccDNA sample by visually assessing the PCR titration (see Note below) and excise a gel slice containing the PCR amplicon corresponding to the size of the desired product using a 100-1,000 μl pipette fitted with gel excision tips. Expel each gel slice into a separate 1.5 ml centrifuge tube.
Note: A bright band corresponding to the ‘empty’ circularized ccDNA product (i.e., without a small RNA insert) should be visible in each lane. This may appear as a doublet as the number of PCR cycles (N) is increased. For most small RNA sequencing applications, the desired product will be ~50 bp above this bright band/doublet. For CRISPR RNA sequencing, we rarely ever see a visible smear at this size range, and cut ‘blindly’ using the DNA ladder and the location of the bright band/doublet (~125 bp) as a visual guide. We typically aim for the highest number of PCR cycles for each ccDNA sample while still safely avoiding the upward-smear from the bright ~125 bp band/doublet (Figure 5).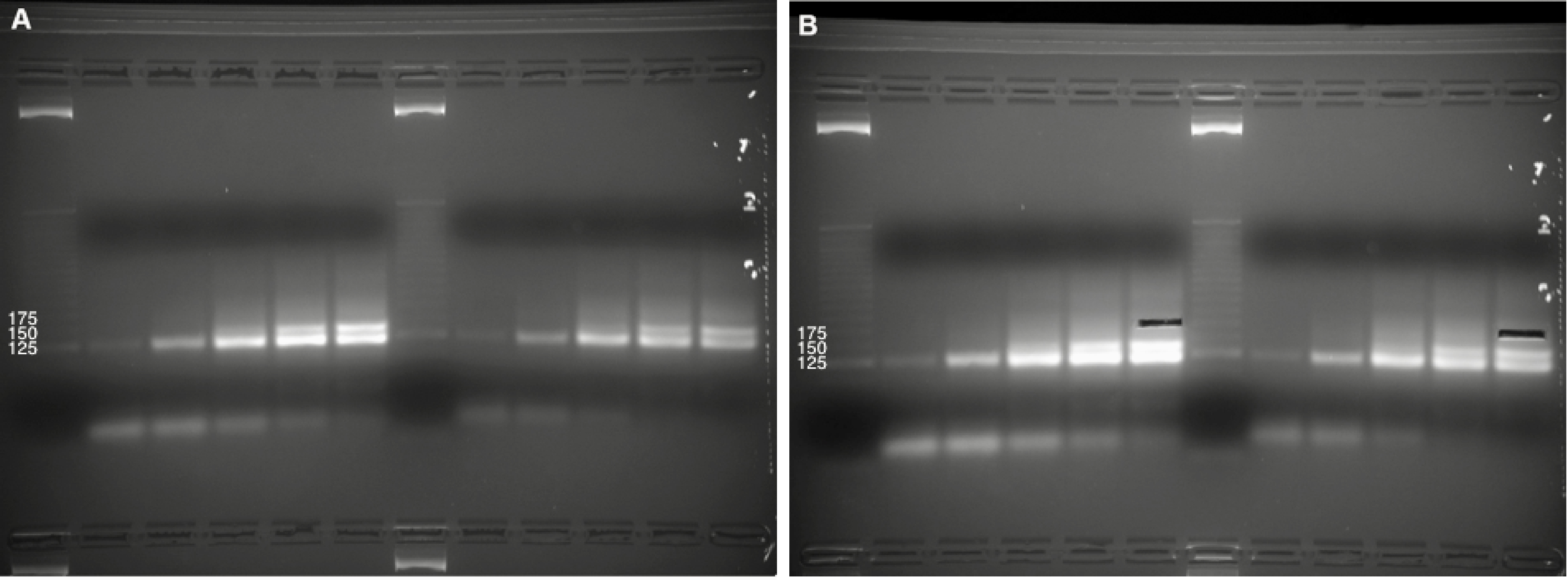
Figure 5. Library preparation by ‘blind’ gel excision. A. PCR titrations of amplified sequencing libraries for two ccDNA samples (3-3.5% native agarose gel electrophoresis). 5 titrations for each ccDNA sample were run side-by-side along with a DNA sizing ladder. Brightness/contrast adjusted in Microsoft Word. B. Size selection of DNA at the 175 bp marker, above the bright band/doublet formed by amplification from empty ccDNA (i.e., without a small RNA insert). The Invitrogen 25 bp DNA ladder was used in this gel but has since been discontinued by the manufacturer. - Extract DNA from the gel slices according to manufacturer’s instructions using the QIAGEN MinElute Gel Extraction kit.
- Quantify each purified DNA sample according to manufacturer’s instructions using the high-sensitivity double stranded DNA quantification kit accompanying the Qubit fluorometer.
- Calculate the approximate concentration of each sample according to the following formula:
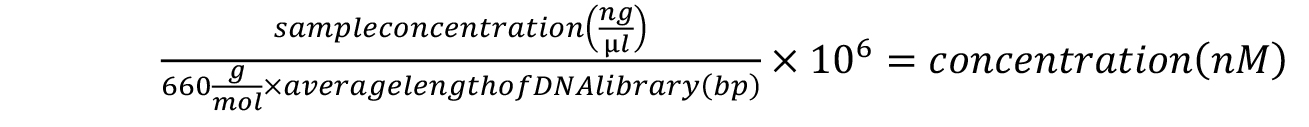
- Pool the samples in equimolar amounts. The pooled library can be sequenced according to the specifications of your Illumina high-throughput sequencing services provider. We typically use the single-read configuration for 80 cycles for small RNA sequencing applications. For assessing pre-crRNA processing in Marinomonas mediterranea, we sequence no more than 1 million reads per sample, but this will depend on the level of expression of pre-crRNA in the species of interest.
- Prepare a PCR mix with 100 μl 2x Phusion Master Mix, 1 μl (100 μM) Universal PCR primer, and 100 μl water for each cDNA sample.
Data analysis
We include a worked example with sample data, which requires the following programs to be installed:
cutadapt (tested on v1.14; likely compatible with most other versions)
Python 2.7 (with numpy, matplotlib for plotting)
The usage formats of the provided python scripts are in bold italics, followed by the specific commands in bold for the worked example with sample data. Start by downloading the worked example, and navigating to the worked_example/ directory in a unix terminal.
- Demultiplex reads: Obtain the high-throughput sequencing data in ‘fastq’ format.
- Sample and index reads will be in files Undetermined_S0_L001_R1_001.fastq and Undetermined_S0_L001_I1_001.fastq respectively, with the first read corresponding to the first index, the second read corresponding to the second index, and so on. A sample dataset is provided in the sample_data directory.
- To segregate reads corresponding to each index, prepare a demultiplexing ‘key’–a tab separated text file with the first column containing the desired sample name, and the second containing the reverse complement of the corresponding TruSeq LT index (AD001-8). A sample file deMultiplexKey_sample.dat is provided.
- Now run the deMultiplexer.py file as follows:
python deMultiplexer.py <path_to_directory> <key>
e.g., python deMultiplexer.py sample_data/ deMultiplexKey_sample.dat
This generates a FASTQ file for each index provided in the key. Note how the files for samples 1-4 in the provided example are empty. The example dataset only contains reads corresponding to the index reads provided for samples 5-8.
Move demultiplexed data (samples 5-8) to a separate directory
mkdir sample_demultiplexed
cd sample_data/
mv sample[5-8]*.fastq ../sample_demultiplexed/
cd ../
- Sample and index reads will be in files Undetermined_S0_L001_R1_001.fastq and Undetermined_S0_L001_I1_001.fastq respectively, with the first read corresponding to the first index, the second read corresponding to the second index, and so on. A sample dataset is provided in the sample_data directory.
- Trim adapters: The high-throughput sequencing data will contain Illumina adapter sequences. These are parts of the molecule that were necessary for sequencing on the Illumina flowcell.
- Collapse reads to eliminate amplification bias: The assay design includes a random hexamer (NNNNNN) in the 3’ adapter sequence, which is ligated to every RNA molecule before reverse-transcription. This helps eliminate amplification bias in downstream steps and helps ensure that every read corresponds to a distinct RNA molecule in the biological sample.
Both Steps 2 and 3 (trimming and collapsing) are performed in the provided example with the dirRNAseqAnalyse.py script (using the readCollapser2.py function, which must be in the same directory as the script) as follows:python dirRNAseqAnalyse.py <path_to_directory> <maximum_read_length>
e.g., python dirRNAseqAnalyse.py sample_demultiplexed/ 80
The program produces a log file dirRNAseqAnalyseLog.txt which contains details of the adapter trimming step. - Convert to fasta: The fastq2fasta.sh script has been prepared anticipating the files that will be generated in Step 3 for sample data. Each line in this script processes one input fastq file to one output fasta file. Modify this file with your input files (with .trimmed.collapsed.fastq extensions) and output files (with .fasta extensions) as desired. Convert using the following commands:
- Run the provided fastqtofasta.sh script:
sh fastq2fasta.sh
Move the trimming intermediates to a new directory:
mkdir sample_trimmed_collapsed
mv *.trimmed* sample_trimmed_collapsed/ - Move the .fasta files to a new directory:
mkdir sample_fasta
mv *.fasta sample_fasta/
- Run the provided fastqtofasta.sh script:
- Filtering:
- Identify CRISPR derived reads: First, identify sequencing reads containing the 5’ end of the CRISPR direct repeat sequence. We require at least 5 contiguous bases in the sequencing read to match the first five bases of the CRISPR repeat. The CRISPR repeat of interest is supplied in the 1st line of the parameters file crRNAfigureMaker_params.txt. Any sequence upstream of the start of the CRISPR repeat is removed.
- Remove short matches: If the resulting processed repeat is shorter than 12 bases, also check to see if the 5 bases preceding the CRISPR repeat in the original read match one of the possible spacer endings from the CRISPR arrays in the bacterial genome. In this way, we require at least 12 bases from the CRISPR repeat, or 10 bases across the spacer-repeat junction for any read to qualify for downstream analysis. A dictionary of all possible native spacer endings from the type III-B CRISPR locus in the Marinomonas mediterranea MMB-1 genome is provided in spacerEnds.dict.
Note: The spacerEnds.dict file can be modified in any text editor, but its formatting must be preserved to prevent parsing errors in python. - Assess match fidelity: If the read passes initial filtering, the processed repeat is then matched to the expected CRISPR repeat sequence. We require the repeat to be a left-anchored substring of the CRISPR repeat (i.e., the processed repeat may be shorter than the CRISPR repeat, but it must match at the 5’ end and cannot contain mismatches).
- Identify CRISPR derived reads: First, identify sequencing reads containing the 5’ end of the CRISPR direct repeat sequence. We require at least 5 contiguous bases in the sequencing read to match the first five bases of the CRISPR repeat. The CRISPR repeat of interest is supplied in the 1st line of the parameters file crRNAfigureMaker_params.txt. Any sequence upstream of the start of the CRISPR repeat is removed.
- Measure levels of a reference gene: Next, count reads containing 25-nt substrings of a reference gene that is highly expressed and does not vary with the biological conditions under study. We use the isoleucine-tRNA sequence as a reference in M. mediterranea datasets, but this may need to be empirically determined based on your RNAseq data for your model. This sequence must be provided in the 2nd line of the crRNAfigureMaker_params.txt file.
- Plot a histogram of lengths of trimmed reads: Finally, plot a histogram of the lengths of the processed CRISPR repeats normalized to the reference gene. The 3rd line of the crRNAfigureMaker_params.txt file is an arbitrary scaling parameter that controls the height of the Y axis in the plot. It can be changed to accommodate the levels of processed crRNAs relative to the reference gene in your dataset.
Steps 5, 6, and 7 are performed by the crRNAfigureMaker.py script as follows:python crRNAfigureMaker.py <path_to_fasta_files> <keyword>
e.g., python crRNAfigureMaker.py sample_fasta/ 8
The keyword option specifies which files should be included in the analysis. The keyword can be any part of the file name. For instance, using the keyword ‘8’ will only process sample8.fasta in the worked example, while using the keyword ‘mpl’ will include all 4 sample files for processing, and using the keyword ‘sem’ will result in no files being included.
The crRNAfigureMaker_param.txt file must be in the same directory as the code. Running the above command (i.e., only processing sample8.fasta) should generate Figure 6 below.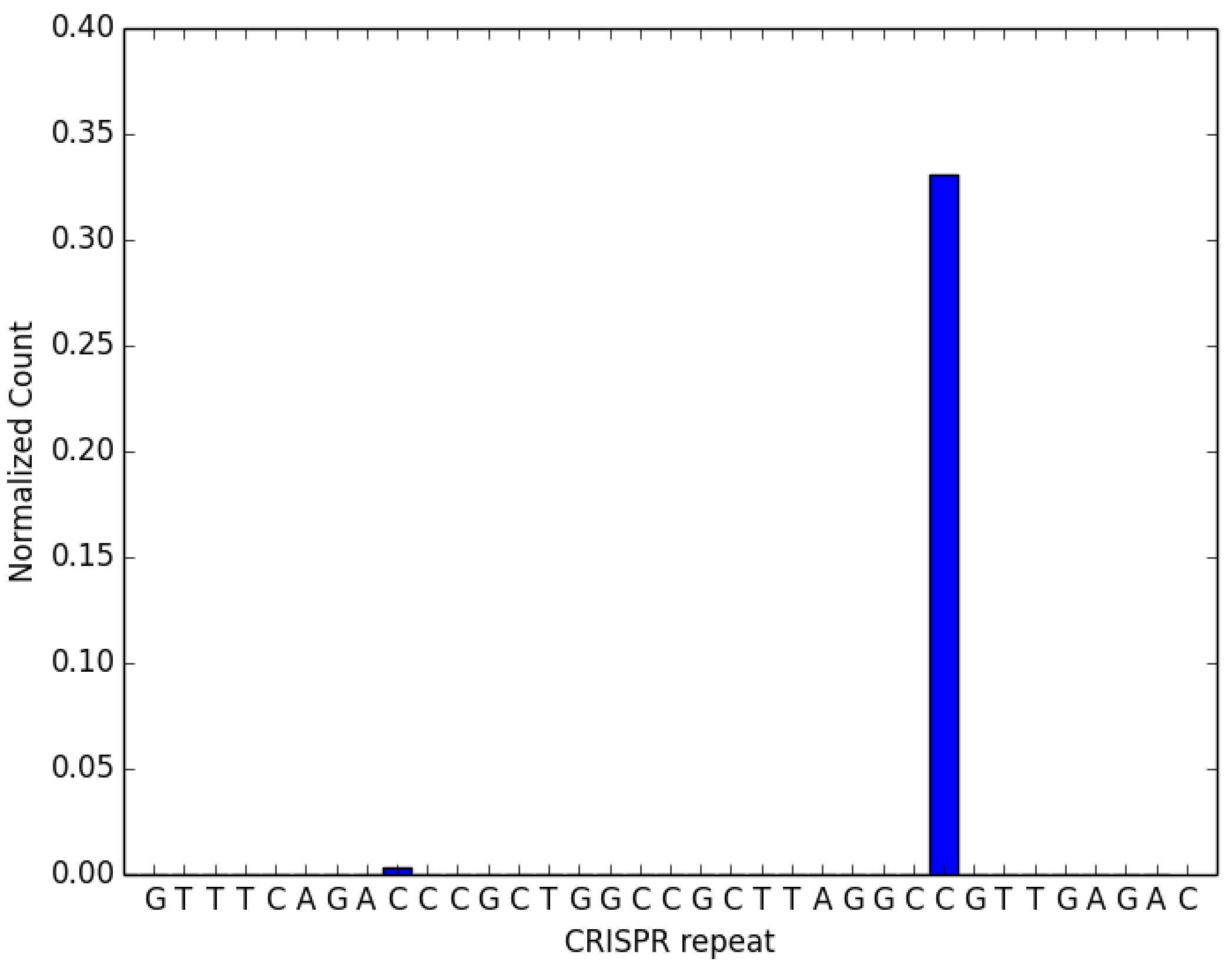
Figure 6. Expected output of code provided in the worked example. Processed crRNA levels assayed by high throughput small RNA sequencing. This dataset has been artificially supplemented with sequences matching expected CRISPR-derived RNAs. The CRISPR repeat sequence from the 1st line of the parameters file crRNAfigureMaker_params.txt is on the X-axis. The height of the bar at each base along the X-axis represents the relative proportion of crRNAs with 3’ ends at that base, normalized to the levels of the reference RNA (isoleucine tRNA; consistently the most abundant species encountered in our M. mediterranea datasets). The presence of a distinct 3’ end sequence in the population of CRISPR repeat containing RNAs indicates site-specific cleavage and processing of pre-crRNA.
The data files in the worked example are small subsets of our experimental data and have been artificially supplemented with sequences matching expected CRISPR-derived RNAs. Please refer to our public datasets at the NCBI Short Read Archive (SRP103952) to recreate the published graphs (Silas et al., 2017a). The following table specifies the accession numbers for the experiments that correspond to each of the relevant figure panels in (Silas et al., 2017a).
Recipes
- Polyacrylamide gel elution buffer
300 mM NaCl
1 mM EDTA
To make 50 ml:3 ml 5 M sodium chloride solution 500 μl 0.1 M EDTA solution 46.5 ml RNase free water - 1 M HEPES/KOH buffer pH 8.3
Adjust the pH of 1 M HEPES solution with 8 N potassium hydroxide to 8.3
Sterile filter using a 0.2 μm vacuum filtration unit - 60% glycerol solution
To make 10 ml, mix 6 ml glycerol with 4 ml RNase-free water
Sterilize by autoclaving - 5x adenylation buffer
Note: Store in 1 ml aliquots at -20 °C up to 1 year.
41% glycerol
250 mM HEPES/KOH pH 8.3
50 mM MgCl2
16.5 mM DTT
50 μg/ml Ac-BSA
To make 5 ml, mix:3.4 ml 60% glycerol solution 1.25 ml 1 M HEPES/KOH buffer pH 8.3 250 μl 1 M magnesium chloride solution 82.5 μl 1 M dithiothreitol solution 12.5 μl 20 mg/ml acetylated BSA
Acknowledgments
S.S. was supported by a Stanford Graduate Fellowship and an HHMI International Student Research Fellowship. This protocol was developed with support from the NIH (grant R01-GM37706 to A.Z.F.). We adapted earlier RNA sequencing methods (Lau et al., 2001; Ingolia et al., 2009; Guo et al., 2010; Kwon, 2011) for RNA sequencing from C. elegans (Lamm et al., 2011), incorporated others’ work on unique molecular identifiers to remove PCR duplicates (Kivioja et al., 2011), and introduced enzymatic cleanup steps (5’ deadenylase/RecJ) to circumvent a gel purification step. We have found this protocol useful for a variety of RNA sequencing applications, such as crRNA detection (Silas et al., 2017a), prokaryotic transcriptome profiling (Silas et al., 2016), sequencing RNA from metagenomic environmental samples (Silas et al., 2017b), and ribosome footprinting (Arribere et al., 2016). We declare that we have no competing interests or conflicts of interest.
References
- Arribere, J. A., Cenik, E. S., Jain, N., Hess, G. T., Lee, C. H., Bassik, M. C. and Fire, A. Z. (2016). Translation readthrough mitigation. Nature 534(7609): 719-723.
- Barrangou, R., Fremaux, C., Deveau, H., Richards, M., Boyaval, P., Moineau, S., Romero, D. A. and Horvath, P. (2007). CRISPR provides acquired resistance against viruses in prokaryotes. Science 315(5819): 1709-1712.
- Brouns, S. J., Jore, M. M., Lundgren, M., Westra, E. R., Slijkhuis, R. J., Snijders, A. P., Dickman, M. J., Makarova, K. S., Koonin, E. V. and van der Oost, J. (2008). Small CRISPR RNAs guide antiviral defense in prokaryotes. Science 321(5891): 960-964.
- Carte, J., Pfister, N. T., Compton, M. M., Terns, R. M. and Terns, M. P. (2010). Binding and cleavage of CRISPR RNA by Cas6. RNA 16(11): 2181-2188.
- Carte, J., Wang, R., Li, H., Terns, R. M. and Terns, M. P. (2008). Cas6 is an endoribonuclease that generates guide RNAs for invader defense in prokaryotes. Genes Dev 22(24): 3489-96.
- Charpentier, E., Richter, H., van der Oost, J. and White, M. F. (2015). Biogenesis pathways of RNA guides in archaeal and bacterial CRISPR-Cas adaptive immunity. FEMS Microbiol Rev 39(3): 428-441.
- Deveau, H., Barrangou, R., Garneau, J. E., Labonte, J., Fremaux, C., Boyaval, P., Romero, D. A., Horvath, P. and Moineau, S. (2008). Phage response to CRISPR-encoded resistance in Streptococcus thermophilus. J Bacteriol 190(4): 1390-1400.
- Guo, H., Ingolia, N. T., Weissman, J. S. and Bartel, D. P. (2010). Mammalian microRNAs predominantly act to decrease target mRNA levels. Nature 466(7308): 835-840.
- Haurwitz, R. E., Jinek, M., Wiedenheft, B., Zhou, K. and Doudna, J. A. (2010). Sequence- and structure-specific RNA processing by a CRISPR endonuclease. Science 329(5997): 1355-1358.
- Heidrich, N., Dugar, G., Vogel, J. and Sharma, C. M. (2015). Investigating CRISPR RNA biogenesis and function using RNA-seq. Methods Mol Biol 1311: 1-21.
- Hochstrasser, M. L. and Doudna, J. A. (2015). Cutting it close: CRISPR-associated endoribonuclease structure and function. Trends Biochem Sci 40(1): 58-66.
- Ingolia, N. T., Ghaemmaghami, S., Newman, J. R. and Weissman, J. S. (2009). Genome-wide analysis in vivo of translation with nucleotide resolution using ribosome profiling. Science 324(5924): 218-223.
- Jackson, S. A., McKenzie, R. E., Fagerlund, R. D., Kieper, S. N., Fineran, P. C. and Brouns, S. J. (2017). CRISPR-Cas: Adapting to change. Science 356(6333).
- Juranek, S., Eban, T., Altuvia, Y., Brown, M., Morozov, P., Tuschl, T. and Margalit, H. (2012). A genome-wide view of the expression and processing patterns of Thermus thermophilus HB8 CRISPR RNAs. RNA 18(4): 783-794.
- Kivioja, T., Vaharautio, A., Karlsson, K., Bonke, M., Enge, M., Linnarsson, S. and Taipale, J. (2011). Counting absolute numbers of molecules using unique molecular identifiers. Nat Methods 9(1): 72-74.
- Kwon, Y. S. (2011). Small RNA library preparation for next-generation sequencing by single ligation, extension and circularization technology. Biotechnol Lett 33(8): 1633-1641.
- Lamm, A. T., Stadler, M. R., Zhang, H., Gent, J. I. and Fire, A. Z. (2011). Multimodal RNA-seq using single-strand, double-strand, and CircLigase-based capture yields a refined and extended description of the C. elegans transcriptome. Genome Res 21(2): 265-275.
- Lau, N. C., Lim, L. P., Weinstein, E. G. and Bartel, D. P. (2001). An abundant class of tiny RNAs with probable regulatory roles in Caenorhabditis elegans. Science 294(5543): 858-862.
- Makarova, K. S., Haft, D. H., Barrangou, R., Brouns, S. J., Charpentier, E., Horvath, P., Moineau, S., Mojica, F. J., Wolf, Y. I., Yakunin, A. F., van der Oost, J. and Koonin, E. V. (2011). Evolution and classification of the CRISPR-Cas systems. Nat Rev Microbiol 9(6): 467-477.
- Makarova, K. S., Wolf, Y. I., Alkhnbashi, O. S., Costa, F., Shah, S. A., Saunders, S. J., Barrangou, R., Brouns, S. J., Charpentier, E., Haft, D. H., Horvath, P., Moineau, S., Mojica, F. J., Terns, R. M., Terns, M. P., White, M. F., Yakunin, A. F., Garrett, R. A., van der Oost, J., Backofen, R. and Koonin, E. V. (2015). An updated evolutionary classification of CRISPR-Cas systems. Nat Rev Microbiol 13(11): 722-736.
- Marraffini, L. A. and Sontheimer, E. J. (2008). CRISPR interference limits horizontal gene transfer in staphylococci by targeting DNA. Science 322(5909): 1843-1845.
- Plagens, A., Richter, H., Charpentier, E. and Randau, L. (2015). DNA and RNA interference mechanisms by CRISPR-Cas surveillance complexes. FEMS Microbiol Rev 39(3): 442-463.
- Richter, H., Zoephel, J., Schermuly, J., Maticzka, D., Backofen, R. and Randau, L. (2012). Characterization of CRISPR RNA processing in Clostridium thermocellum and Methanococcus maripaludis. Nucleic Acids Res 40(19): 9887-9896.
- Silas, S., Lucas-Elio, P., Jackson, S. A., Aroca-Crevillen, A., Hansen, L. L., Fineran, P. C., Fire, A. Z. and Sanchez-Amat, A. (2017a). Type III CRISPR-Cas systems can provide redundancy to counteract viral escape from type I systems. Elife 6.
- Silas, S., Makarova, K. S., Shmakov, S., Paez-Espino, D., Mohr, G., Liu, Y., Davison, M., Roux, S., Krishnamurthy, S. R., Fu, B. X. H., Hansen, L. L., Wang, D., Sullivan, M. B., Millard, A., Clokie, M. R., Bhaya, D., Lambowitz, A. M., Kyrpides, N. C., Koonin, E. V. and Fire, A. Z. (2017b). On the origin of reverse transcriptase-using CRISPR-Cas systems and their hyperdiverse, enigmatic spacer repertoires. MBio 8(4).
- Silas, S., Mohr, G., Sidote, D. J., Markham, L. M., Sanchez-Amat, A., Bhaya, D., Lambowitz, A. M. and Fire, A. Z. (2016). Direct CRISPR spacer acquisition from RNA by a natural reverse transcriptase-Cas1 fusion protein. Science 351(6276): aad4234.
Article Information
Copyright
![]() Silas et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
Silas et al. This article is distributed under the terms of the Creative Commons Attribution License (CC BY 4.0).
How to cite
Readers should cite both the Bio-protocol article and the original research article where this protocol was used:
- Silas, S., Jain, N., Stadler, M., Fu, B. X. H., Sanchez-Amat, A., Fire, A. Z. and Arribere, J. (2018). A Small RNA Isolation and Sequencing Protocol and Its Application to Assay CRISPR RNA Biogenesis in Bacteria. Bio-protocol 8(4): e2727. DOI: 10.21769/BioProtoc.2727.
- Silas, S., Lucas-Elio, P., Jackson, S. A., Aroca-Crevillen, A., Hansen, L. L., Fineran, P. C., Fire, A. Z. and Sanchez-Amat, A. (2017a). Type III CRISPR-Cas systems can provide redundancy to counteract viral escape from type I systems. Elife 6.
Category
Microbiology > Microbial genetics > RNA > Sequencing
Molecular Biology > RNA > RNA sequencing
Do you have any questions about this protocol?
Post your question to gather feedback from the community. We will also invite the authors of this article to respond.